

What's

Dec 20. 2023
Research Visit at the Eindhoven University of Technology
Branislav Pecher is one of our PhD students, he is a member of the Web & User Data Processing team where he focuses on learning models that involve only a limited number of annotated samples, particularly in-context learning, transfer learning and meta-learning. In August 2023, Branislav had a wonderful opportunity to do a research visit thanks to the TAILOR project. Read on to find out more about his experience at the Eindhoven University of Technology and the project he worked on.
The current state of deep learning is dominated by using massive datasets to train a large neural network to perform a specific task. Even though using the full dataset often leads to high performance, there are 2 problems present:
1) For many domains, such as misinformation detection, it is difficult to gather large amounts of labelled data.
2) Recent studies found that the quality of samples in the massive datasets is often more important than their quantity. As there are many low-quality samples that either provide no information, or information that may be misleading when training the model on the dataset, the performance may suffer if they are not filtered out.
As I am interested in efficient learning with limited labelled data, the interesting part for me is the intersection between these 2 problems – what is the impact of data quality on the performance when dealing with limited labelled data?
This research problem was the main focus of the project I was working on during my research visit at the Eindhoven University of Technology in Netherlands. During the research visit, I have worked with the Automated Machine Learning Group led by Joaquin Vanschoren. Joaquin is one of the top leading experts in efficient and automated machine learning, which includes topics such as continual learning, transfer learning or meta-learning. The visit was supported by the TAILOR Collaboration Exchange Fund.

Research Visit Project – Effective Sample Selection
As the first step of the project, we have analysed the existing works that focus on sample selection across various domains. There is a plethora of research for this problem, as the efficient learning with a small number of samples is a long sought after goal.
As such, many selection strategies already exist:
1) Active learning strategies choose samples from unlabelled data that should be annotated in order to reduce the load on annotators, while still providing the most informative samples.
2) Core-set selection strategies are designed to choose a representative subset of a larger annotated dataset, i.e., a subset that has similar characteristics and leads to similar performance.;
3) Quality/Heuristics based strategies are designed to choose the samples of highest quality based on some kind of heuristics (length of text, how easy/hard it is to learn the specific samples, or how much performance increase the specific sample contributes).
Although there are many different sample selection strategies, their benefit was so far evaluated on more simple classification settings. As such, the benefit for few-shot learning, where the trained model needs to adapt to previously unseen tasks and classes, is still not sufficiently explored.
Based on the findings of our analysis, we have decided to investigate and evaluate the benefit of a subset of best-performing sample selection strategies on the few-shot setting, using meta-learning and few-shot fine-tuning approaches. We compared them with the performance of a simple baseline where the samples are chosen randomly. The sample selection strategies have shown they can increase the overall performance of the adaptation to the previously unseen tasks by 2% on average. However, the sample selection strategies have shown a significant dataset and model dependence, with the most beneficial strategy being different across the investigated models and datasets. In addition, the investigation was done only on a single strategy at the same time, while the benefit of their combination is largely missing (even in previous studies).
This opens up a further research question and problem – does the combination of different sample selection strategies provide larger benefits and can this combination be effectively and efficiently found? The exhaustive search through all the sample selection strategies combination should lead to the highest possible benefit, but is infeasible to do for every dataset and model – as it requires a significant amount of computational resources.
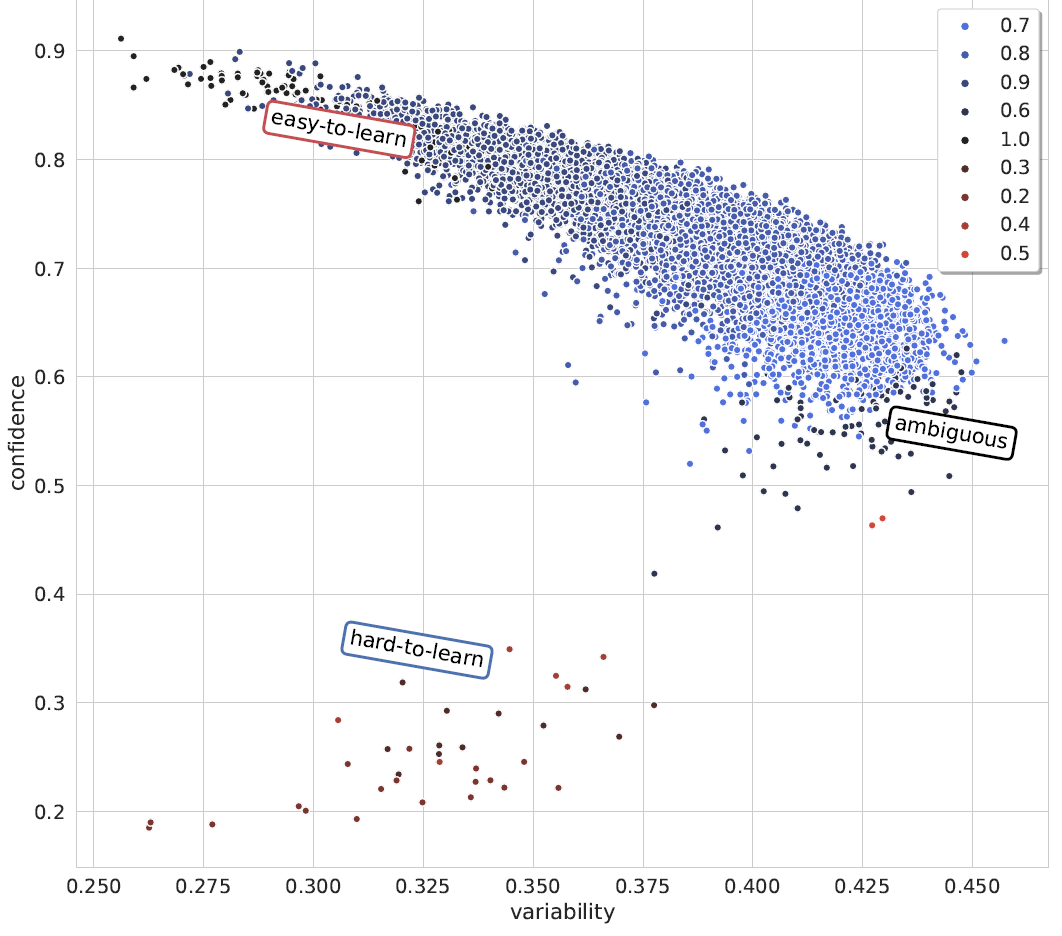
Therefore, as the second step of the project, we have decided to look at how to efficiently combine different strategies. We designed 3 separate strategies for exploring the different combinations, inspired by previous works (e.g., Chang and Jia, 2023, Ilyas et al., 2022, Vilar et al., 2023). Two of them were similar to feature selection (forward and backward selection) and one was based on regularised linear regression. Using these strategies, we have identified a combination of sample selection strategies that provides the most significant benefit, which is also consistent across all the investigated models and datasets – i.e., making the combination general as it does not show any dataset or model dependence.
Selecting samples on the decision boundary that are the easiest to learn, provides the most benefit for few-shot learning when adapting to previously unseen tasks and classes. Such a strategy can provide an additional 1-2% performance benefit on average.
This is an interesting finding that deserves further investigation. As we worked only with few datasets, despite the research visit being over, the next steps with this project include its extension to further datasets, both image and text, in order to make the findings more generalisable. In addition, focusing on sample selection in an in-context learning setting (usable only for text data) is another avenue of future work – as the choice of samples was shown as one of the most significant factor that influences the performance and stability of different in-context learning models.
Research Visit Experience and Benefits
As stated previously, this project was done as a part of the research visit supported by the TAILOR Collaboration Exchange Fund. During the visit, I cooperated with the AutoML group at the Eindhoven University of Technology led by professor Joaquin Vanschoren.
The research visit was an excellent and unique opportunity for me. First of all, it allowed me to discuss the research topic and problem with other expert researchers. We had many fruitful and interesting discussions, not only on the topic of the research project but also on other concepts in efficient machine learning and deep learning. In addition, it allowed me to experience how other researchers handle the research problems, with an insight into how the research questions are formulated, how the research methodology and experiments are designed.
Finally, the visit allowed me to expand my personal network with top level researchers in my research area, the new connection might lead to possible future collaborations. For example, we still continue working on the research visit project. Through active participation and regular consultations and presentations, I believe I have improved my capabilities as a researcher. All of these things have positively contributed to my professional growth and allowed me to deepen my expertise in machine learning research.
Not only did I make new contacts with researchers working on the same topic, but for a little while I became a part of the University and took part in the Eindhoven Marathon as a part of the University Team in the 5k event.

Besides the personal development, the research visit has also contributed to my research. The project I have worked on during the research visit is an integral part of my dissertation topic. As such, engaging with researchers in my field, many insightful discussions and valuable feedback has significantly contributed to improving my work on the dissertation thesis as a whole.
Although the research visit is already over, we are still working on the project, on its extension to improve the generalisability of its results and findings. We are planning to summarise the results in a joint paper that we plan to submit to the ICML 2024 conference.
All in all, the research visit was a great experience with a lot of benefits and opportunities for professional and personal growth. I believe it has helped me grow as a researcher and had a positive impact on my PhD studies as well.

