


Čo je

dec 20. 2023
Výskumná návšteva na Technickej univerzite v Eindhovene
Branislav Pecher je jeden z našich doktorandov. Ako člen tímu WUDAP sa zameriava na učiace sa modely, ktoré zahŕňajú iba obmedzený počet anotovaných vzoriek. Venuje sa predovšetkým učeniu s kontextom (angl. In-context learning), prenosovému učeniu s prenosom a meta-učeniu. V auguste 2023 dostal Branislav výnimočnú príležitosť absolvovať v rámci projektu TAILOR výskumnú návštevu. Čítajte ďalej a dozviete sa viac o jeho skúsenostiach na Technickej univerzite v Eindhovene a o projekte, na ktorom tam pracoval.
Aktuálna situácia v oblasti hlbokého učenia vyzerá tak, že na trénovanie veľkých neurónových sietí na použitie na konkrétnu úlohu sa využívajú obrovské datasety. Aj keď využitie veľkého datasetu vedie k modelom s vysokou úspešnosťou, vyskytujú sa tam dva hlavné problémy:
1) Pre mnohé oblasti, ako napríklad detekcia dezinformácií, predstavuje získanie dostatočného množstva označených dát veľkú výzvu.
2) Nedávne štúdie ukázali, že kvalita vzoriek v datasetoch je často dôležitejšia než ich množstvo, keďže existuje množstvo vzoriek nízkej kvality, ktoré buď neponúkajú žiadne informácie alebo poskytujú informácie, ktoré sú zavádzajúce pri trénovaní modelu. Preto je dôležité, aby boli tieto vzorky adekvátne filtrované. Ich prítomnosť bez správneho filtrovania môže negatívne ovplyvniť úspešnosť modelu.
Keďže ma téma efektívneho učenia s obmedzeným množstvom označených údajov fascinuje, prepojenie týchto dvoch problémov je pre mňa veľmi zaujímavé. Aký vplyv má kvalita údajov na výkonnosť pri práci s obmedzeným množstvom označených údajov?
Tento výskumný problém bol hlavnou témou projektu, na ktorom som pracoval počas mojej výskumnej návštevy na Technickej univerzite v Eindhovene. Počas svojej návštevy som spolupracoval s tímom Automated Machine Learning pod vedením Joaquina Vanschorena. Joaquin je jedným z vedúcich odborníkov v oblasti efektívneho a automatizovaného strojového učenia. Táto oblasť zahŕňa témy ako kontinuálne učenie, učenie s prenosom a meta-učenie. Výskumná návšteva bola realizovaná s finančnou podporou TAILOR Collaboration Exchange Fund.

Projekt výskumnej návštevy: Efektívny výber vzoriek
Ako prvý krok nášho projektu sme analyzovali už existujúce práce zamerané na výber vzoriek v rôznych oblastiach. Týmtom výskumným problémom sa zaoberá množstvo výskumníkov, keďže efektívne učenie s využitím malého počtu vzoriek je niečo, o čo sa výskum v umelej inteligencii dlhodobo snaží.
V tejto oblasti už poznáme mnoho stratégií výberu vzoriek:
1) Stratégie aktívneho učenia vyberajú vzorky z neoznačených údajov, ktoré by mali byť následne anotované, s cieľom znížiť zaťaženie anotátorov. Zároveň poskytujú najinformatívnejšie vzorky.
2) Stratégie výberu základnej množiny sú navrhnuté na výber reprezentatívnej podmnožiny väčšieho anotovaného datasetu, t.j. podmnožiny s podobnými charakteristikami, ktoré vedú k podobným výsledkom.
3) Stratégie založené na kvalite/heuristike majú za cieľ vyberať vzorky najvyššej kvality na základe určitých heuristík (dĺžka textu, obtiažnosť učenia konkrétnych vzoriek alebo prínos výkonnosti konkrétnej vzorky).
Hoci existuje mnoho rôznych stratégií výberu vzoriek, ich prínos bol doteraz hodnotený len v jednoduchších nastaveniach klasifikácie. Z tohto dôvodu zatiaľ nie je prínos pre učenie s malým počtom vzoriek, kde sa musí natrénovaný model prispôsobiť predtým nevideným úlohám a triedam, dostatočne preskúmaný.
Na základe zistení našej analýzy sme sa rozhodli preskúmať a vyhodnotiť prínos podmnožiny najlepších stratégií výberu vzoriek v nastavení učenia s malým počtom vzoriek. Využívali sme pritom prístupy meta-učenia a učenia s prenosom s malým počtom vzoriek. Následne sme ich porovnali s výkonom jednoduchého referenčného modelu, v ktorom boli vzorky vybrané náhodne. Stratégie výberu vzoriek ukázali, že ich pomocou je možné zvýšiť celkový výkon adaptácie na úplne nové úlohy v priemere o 2%. Avšak stratégie výberu vzoriek ukázali aj výraznú závislosť od datasetu a modelu, pričom najvýhodnejšia stratégia bola odlišná v rámci skúmaných modelov a datasetov. Okrem toho bola skúmaná len jedna stratégia v jednom čase. Z tohto dôvodu sme nemohli skúmať výhodu ich kombinácie (a to ani v predchádzajúcich štúdiách).
To otvára ďalšiu výskumnú otázku a problém – poskytuje kombinácia rôznych stratégií výberu vzoriek väčšie výhody a dá sa táto kombinácia efektívne a účinne nájsť? Kompletné preskúmanie všetkých možných kombinácií stratégií výberu vzoriek by malo viesť k najvyššiemu možnému prínosu. Avšak to nie je možné vykonať pre každý dataset, keďže by si to vyžadovalov výrazné množstvo výpočtového času.
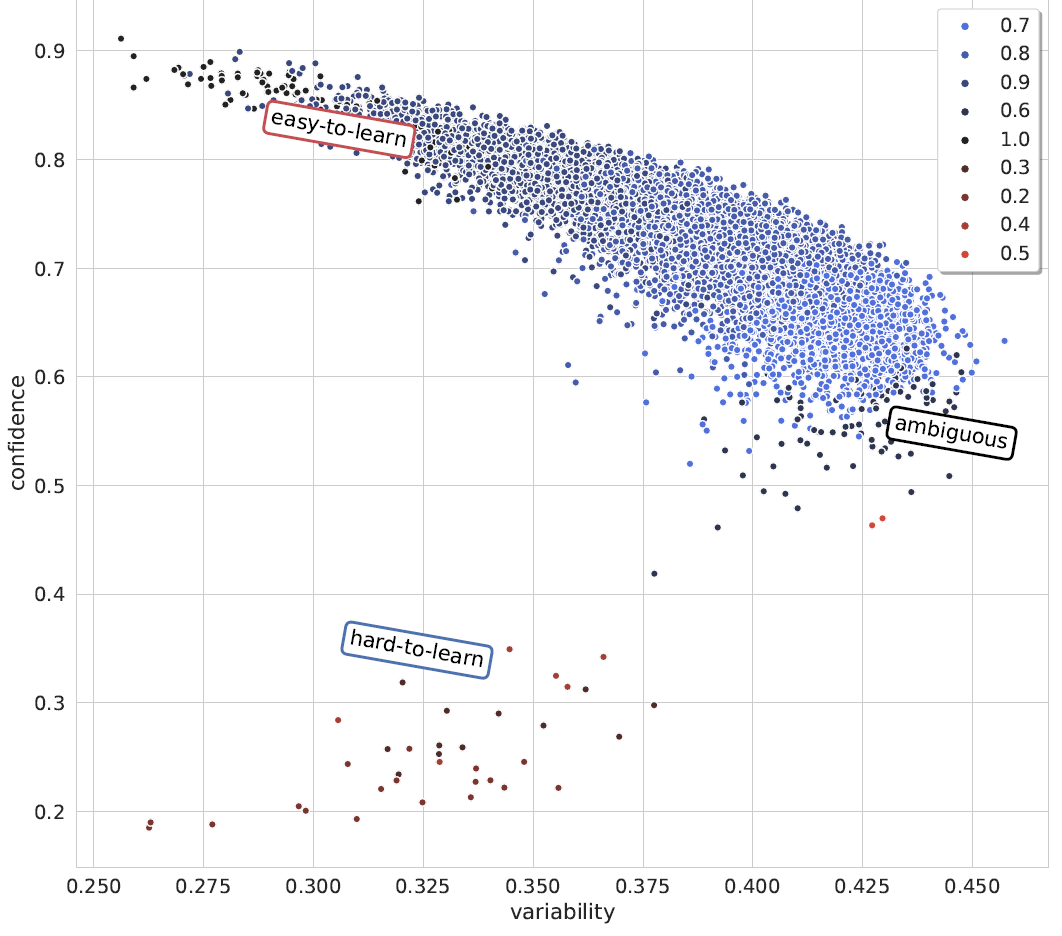
Ako druhý krok nášho projektu sme sa preto rozhodli preskúmať, ako efektívne kombinovať rôzne stratégie. Navrhli sme tri samostatné stratégie na preskúmanie rôznych kombinácií, inšpirované predchádzajúcimi prácami (napr. Chang a Jia, 2023, Ilyas et al., 2022, Vilar et al., 2023). Dve z nich boli inšpirované stratégiami na výber čŕt (dopredná selekcia a spätná selekcia, angl. forward and backward selection), a jedna bola založená na regularizovanej lineárnej regresii. Vďaka týmto stratégiám sme identifikovali kombináciu stratégií výberu vzorky, ktorá poskytuje najvýraznejší prínos, a to naprieč všetkými preskúmanými modelmi a dátovými sadami – teda vytvára kombináciu, ktorá nie je závislá na žiadnej dátovej sade ani modeli.
Vybrať vzorky, ktoré sa nachádzajú na hranici medzi jednotlivými triedami (angl. Decision boundary) a sú jednoduché na naučenie, prináša teda najväčšie výhody pri učení s malým množstvom príkladov, keď je potrebné prispôsobiť sa novým úlohám a triedam. Takáto stratégia môže priemerne zvýšiť výkonnosť o ďalšie 1-2%.
Tento záver je veľmi zaujímavý a verím, že si zaslúži ďalšie preskúmanie. Aj keď sa výskumná návšteva už skončila, v tomto projekte pokračujeme jeho rozšírením na ďalšie dátové sady – obrazové a textové datasety, aby sme mohli získať všeobecnejšie závery. Keďže výber vzoriek sa ukázal ako jeden z najvýznamnejších faktorov ovplyvňujúcich výkonnosť a stabilitu rôznych modelov učenia v kontexte (angl. in-context learning), ďalšou možnou témou do budúcnosti je zameranie sa na výber vzoriek v tomto type učenia (ktoré je však použiteľné len pre textové dáta).
Skúsenosti a prínosy výskumnej návštevy
Ako som už spomínal, projekt bol realizovaný v rámci výskumnej návštevy financovanej za podpory TAILOR Collaboration Exchange Fund. Počas svojho pobytu som spolupracoval s AutoML group na Technickej univerzite v Eindhovene pod vedením profesora Joaquina Vanschorena.
Výskumná návšteva bola pre mňa výnimočnou a jedinečnou príležitosťou. Umožnila mi rozoberať výskumné témy a problémy s ďalšími výskumníkmi, s ktorými sme okrem zaujímavých diskusií o výskumnom projekte rozoberali aj ďalšie koncepty v efektívnom strojovom učení a hlbokom učení. Navyše mi táto stáž ukázala, ako iní výskumníci riešia výskumné problémy, formulujú výskumné otázky a navrhujú metodológiu a experimenty.
V neposlednom rade som si rozšíril môj profesijný okruh o špičkových výskumníkov v mojej oblasti. Tieto nové kontakty môžu v budúcnosti viesť k zaujímavým spoluprácam, ako napríklad pokračovaniu v práci na projekte z výskumnej návštevy. Verím, že účasť na konzultáciách a prezentáciách mi pomohla zlepšiť moje výskumnícke schopnosti. Všetky skúsenosti z výskumnej návštevy nepochybne prispeli k môjmu profesionálnemu rastu a posilnili moje znalosti v oblasti strojového učenia.
Okrem toho, že som naviazal nové kontakty s výskumníkmi pracujúcimi v rovnakom odbore, na chvíľu som sa stal aj súčasťou Univerzity. Napríklad som sa zúčastnil behu na 5 kilometrov v rámci Eidenhovenského maratónu ako člen univerzitného tímu .

Pobyt taktiež prispel aj k môjmu výskumu. Projekt, na ktorom som pracoval je neoddeliteľnou súčasťou mojej dizertačnej témy. Spolupráca s výskumníkmi, bohaté diskusie a spätná väzba výrazne prispeli k zdokonaleniu mojej dizertačnej práce.
Hoci je výskumná návšteva už za mnou, stále pracujeme na rozšírení nášho projektu s cieľom zlepšiť všeobecnosť jeho výsledkov a zistení. Výsledky plánujeme zhrnúť v spoločnom článku, ktorý sa chystáme podať na konferenciu ICML 2024.
Celkovo bola moja výskumná návšteva skvelým zážitkom, ktorý mi priniesol mnoho príležitostí pre profesionálny aj osobný rast. Táto stáž mi poskytla možnosť rozvíjať sa ako výskumník a pozitívne ovplyvnila aj moje doktorandské štúdium.

