


Explainable AI: theory and a method for finding good explanations for (not only) NLP
In two phases of this project, we addressed the problem of finding a good post-hoc explainability algorithm for the task at hand. First, we researched the theory behind what’s a good explanation. Then, we proposed the concept of AutoXAI for finding a well performing explanation algorithm for a combination of model, task and data. We conducted a series of experiments on three different tasks with a particular explainability algorithm – Layer-wise relevance propagation (LRP).
From the perspective of machine learning (ML), we live in happy times. For many tasks we know not one, but many different ML algorithms or models we can select from and achieve at least a decent performance. This wealth of models and their variations introduces a challenge – we need to find such configuration that fits our task and data.
To find the right model, we need to define the criteria that measure how well a particular model and its parameters and hyperparameters fit the problem at hand. Then, we usually do some kind of hyperparameter optimization or Automated Machine Learning (AutoML) [1].
In recent years, the number of post-hoc XAI methods became similarly overwhelming like the number of different machine learning methods. To find a post-hoc explainability algorithm that provides good explanations for the task at hand, we can borrow the concepts from AutoML. Like in AutoML, we have a space of available algorithms and their configurations, and we want to find the one that provides good explanations. The challenging part of AutoXAI is how to compare different explainability algorithms. In other words – what’s a good explanation?
According to multiple authors, a good explanation should balance between two properties – it should faithfully describe a model’s behavior and be understandable for humans.
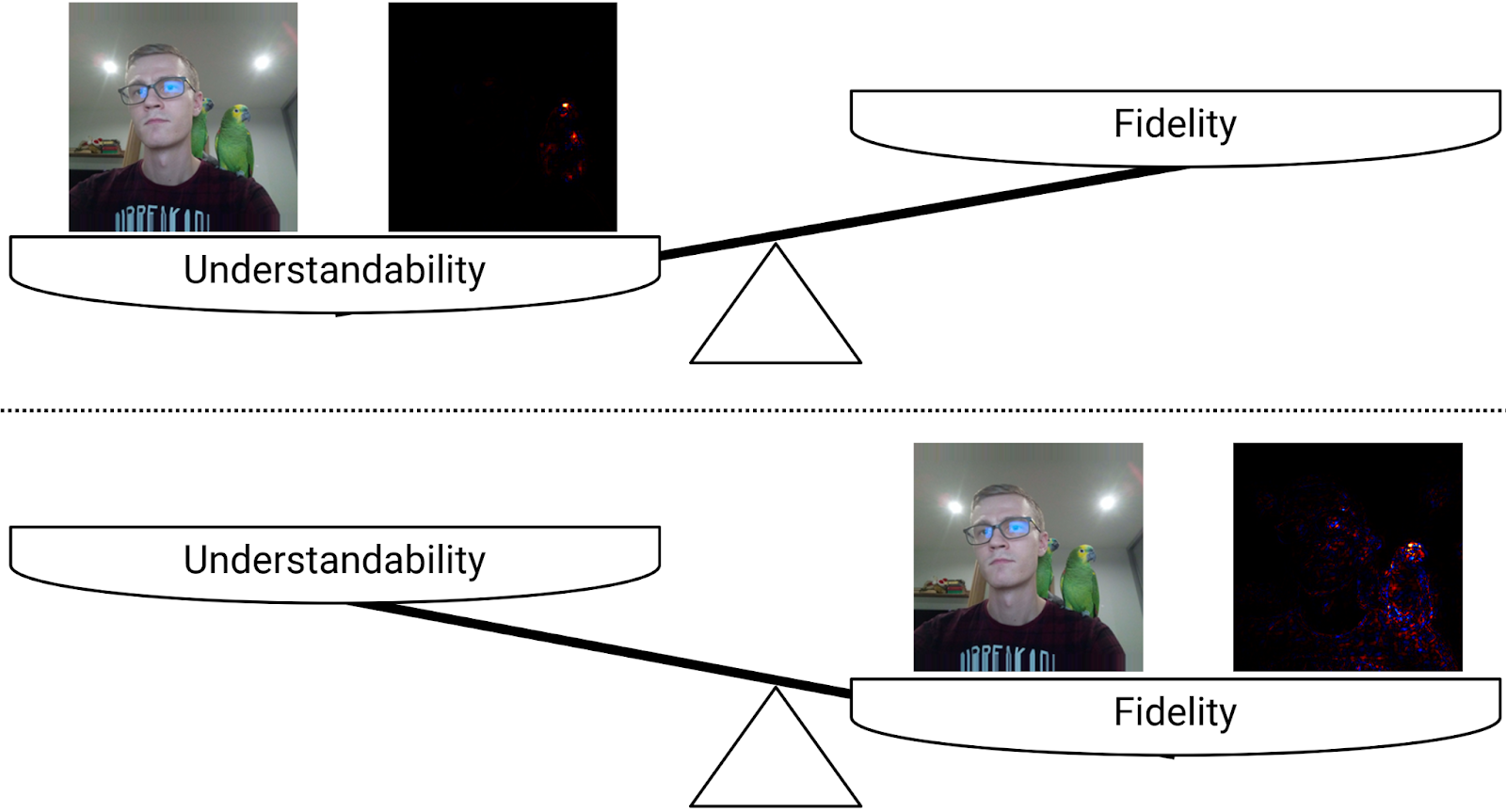
We proposed a definition of AutoXAI as an optimization problem. Through optimization, we want to find an explainability algorithm that maximizes two sets of criteria – understandability and fidelity. These criteria measure the quality of explanations with respect to the underlying model and data.
The first set of criteria, understandability, measures how similar the explanations generated by the explainability algorithm for predictions made by the model are to the explanations that the user considers understandable.
The second set of criteria, fidelity, ensure that the explanations truly reflect the decision-making process of the model.

We conducted three experiments on three different classification tasks. In two tasks, we classified images from magnetic resonance as either healthy or not. In the last task, we classified sentiment of short textual reviews. For these we wanted to find a configuration of a particular explainability algorithm – Layerwise relevance propagation. We proposed three understandability measures that were maximized by using a modified Particle Swarm Optimization in order to obtain understandable explanations.
The results of the proposed method and of the project were presented at the Workshop on Explainable Artificial Intelligence at the International joint conference on artificial intelligence (IJCAI) 2022 in Vienna and at a public seminar organized by KInIT. Proceedings from the conference workshop can be found here.
AutoXAI: Automated Explainable Artificial intelligence
Complex models and especially deep neural networks have introduced unprecedented performance improvements in many tasks.
Despite that, due to their complexity, these models and their decisions tend to be difficult to understand and are perceived as black boxes. Increasing transparency of black box models is addressed by Explainable Artificial Intelligence (XAI). While optimizing a model to solve a task requires non-trivial effort, finding the right human-understandable explanation of a prediction adds another level of complexity to the whole process.
In recent years, the landscape of post-hoc methods in XAI has expanded exponentially, paralleling the growth of diverse machine learning techniques. To select a post-hoc explainability algorithm that yields meaningful explanations for a given task, benefiting the end user, we can draw inspiration from the principles of automated machine learning (AutoML) [1].
Arguably, it is not possible to cover all requirements on XAI with one explainability algorithm – different audiences, models, tasks and data require different explanations. The explanations must also both faithfully explain the predictions and be understandable for the audience. These two properties are in the literature often derived from two components of explainability and explanations – fidelity (or faithfulness) and understandability (or interpretability).
The global goal of the project is to design a way to find such explanations of artificial intelligence decisions that will be faithful and at the same time beneficial to humans. We will build on top of our previous research, part of which was published in the IJCAI-ECAI 2022 workshop dedicated to XAI.
In the first step, we will focus on researching current ways of measuring the quality of explanations. This is still an open research problem, within which the challenge is, among other things, that different types of explanations of the decisions of AI models can be measured in different ways. In addition, it will be necessary to take into account not only how accurately the given metrics describe the quality of the explanations from the point of view of their fidelity (how well they describe the behavior of the model itself), but also how and whether they reflect the usefulness of the explanations for the humans. In this project, we will focus on relevance attribution methods.
In the second step, we propose a method that finds the best explainability method for the task among a number of different explainability methods and their various settings. In doing so, we will use the metrics we identified in the previous step.
To verify the method, we propose a series of experiments in which we will confront the solutions found by the proposed method with how the quality of explanations is evaluated by the addressees themselves – people.
The proposed verification experiments are based on a claim matching task. We will verify to what extent the explanations provided by the explainability algorithms help end users to assess whether a certain disinformation claim was correctly identified in a social media post by a language model. The hypothesis is that the explanations generated by an explainability algorithm optimized through our proposed method should be more helpful to humans with this task than algorithms that achieved lower quality of explanations.
Popularization of Explainable AI
According to the number of papers related to Explainable AI published in recent years, it is clear that this topic drew attention in the scientific community. However, popularization and promotion of Explainable AI in the industry and general public is equally important.
Based on knowledge acquired in our own research and study of relevant scientific literature, we prepared a series of five popularization articles. We covered various topics, from general description of Explainable AI to measuring quality of explanations obtained by using different methods.
Selected aspects of Explainable AI were presented in a technical talk at the Better AI Meetup on November 9th, 2022. You can watch the recording here:
Explainable Artificial Intelligence: From Black Boxes to Transparent Models






Project team

Martin Tamajka

Marcel Veselý

Marián Šimko

Ivana Beňová
The PricewaterhouseCoopers Endowment Fund at the Pontis Foundation supported this project.
References
[1] Frank Hutter, Lars Kotthoff, and Joaquin Vanschoren. Automated machine learning: methods, systems, challenges. Springer Nature, 2019.