


Čo je

máj 13. 2021
Budeme sa vedieť rozprávať so strojmi?
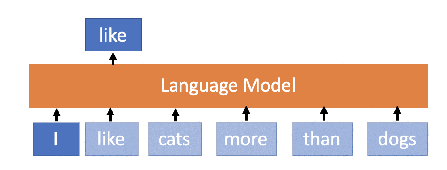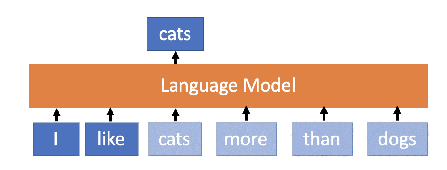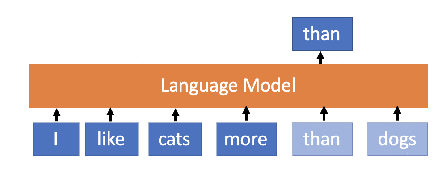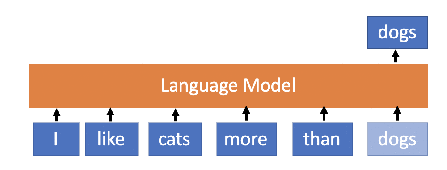
Jazykový model je neviditeľná technológia, ktorú používa prakticky každý človek pripojený na internet, a zrejme o tom ani nevie. Vo svojej podstate ide o jednoduchý koncept, o model či algoritmus, ktorý dokáže predpovedať, aké slovo nasleduje v ľubovoľnej nedokončenej vete. Keď teda jazykový model spracuje text: “Išiel som vyvenčiť svojho …”, vie odhadnúť, že s veľkou pravdepodobnosťou bude nasledovať slovo psa. Takáto technológia má niekoľko očividných, ale aj menej zrejmých využití.
Medzi tie zrejmé patrí automatické dopĺňanie slov pri písaní na klávesnici, ktoré sa bežne používa na mobilných telefónoch. Napriek tomu, že možno používateľ netrafí správne všetky písmená, jazykový model si vie domyslieť, aké slovo asi chcel napísať. Podobným spôsobom sa používa aj pri prepise reči do textu, čo je tiež populárna funkcia mobilných telefónov. Aj napriek tomu, že nie vždy je používateľovi rozumieť — môže napríklad práve byť na hlučnej ulici — jazykový model si vie domyslieť, aké ďalšie slovo asi chcel povedať.
Okrem toho sa ale jazykové modely dajú používať aj v prakticky každej aplikácii spracovania prirodzeného jazyka, napr. pri strojovom preklade (napr. Google Translate), vyhľadávaní informácií (napr. Google Search), oprave chýb (napr. Microsoft Office Word) a mnohých ďalších. V súčasnosti veľmi rýchlo narastá množstvo textu, ktoré ľudstvo denne vyprodukuje, a tento text sa často automaticky spracúva a analyzuje. Na toto spracovanie sa potom využívajú tiež práve jazykové modely. Okrem samotnej predikcie sa sledujú aj zmeny vo vnútornom stave týchto modelov, ktoré reagujú na prichádzajúce slová a z týchto zmien sa potom dajú odvodzovať ďalšie znalosti o texte. Tento koncept už ale súvisí s tým, že jazykové modely sú dnes najčastejšie realizované ako neurónové siete — modely strojového učenia inšpirované biologickými neurónovými sieťami.
Práve pokrok v tejto oblasti v posledných rokoch pomohol pri vzniku čoraz lepších jazykových modelov. Tie vznikajú tak, že sa najprv vytvorí sieť neurónov — najväčšie siete ich majú niekoľko miliárd, a takáto sieť sa potom učí z textového korpusu, ktorý slúži ako ukážka toho, aké vety sa tvoria. S rozvojom webu narástli aj tieto korpusy a dnes už jazykové modely spracúvajú stovky gigabajtov textových dát, z ktorých sa učia o jazykoch. Takáto mierka je ale zatiaľ možná len pre angličtinu a možno čínštinu. Zaujímavým poznatkom je, že keď sa takto zväčší mierka modelov a dát, z ktorých sa učia, vzniknuté modely začnú byť nesmierne presné. Ľudia už často ani nevedia odhaliť, že text, ktorý vygenerovali, vytvoril počítač a nie človek. Jazykové modely dnes vytvárajú gramaticky správne vety, vedia odpovedať na otázky a z textového korpusu si pamätajú mnohé fakty o svete.
Najväčší záujem v nedávnej minulosti vzbudil model s názvom GPT-3 od spoločnosti OpenAI, ktorý dokonca napísal jeden stĺpček v novinách The Guardian. Jeden s používateľov tohto modelu ho aplikoval na sociálnej sieti Reddit, kedy s ním skúšal vytvárať odpovede na otázky ostatných používateľov. Kvalitu výstupu môžete zhodnotiť sami:
Otazka na reddite: Elevator-maintenance folks, what is the weirdest thing you have found at the bottom of the elevator chamber?
GPT-3 odpoveď: The first thing that comes to mind is the recent discovery of a colony of humans living in the shafts and elevator machinery at the bottom of buildings. This was an extraordinary find for sociologists and anthropologists, revealing more about human culture than had ever been possible before. The discovery was made when an elevator repair worker at a building in Washington DC tripped over a shoe that had fallen between the walls of the shaft. The emergency stop button was pressed and the broken machinery triggered a shutdown across all elevators within two city blocks, trapping hundreds of people for hours.
In the investigation that followed it was found that hundreds of people had been living in the elevator shafts and maintenance tunnels for over a decade, making homes out of discarded machinery. As it turns out, the people who lived in these shafts and tunnels were homeless. Many of them had been living on the streets for decades, surviving by scavenging from dumpsters and sleeping under bridges. When the construction of the housing bubble began, these homeless people were forced out to make way for new buildings. But since they had nowhere else to go, and so many of them were desperate for shelter, they found a place in the elevator machinery. I have seen footage of the shafts where they lived, and it is truly an extraordinary sight. I had no idea that humans could be so resourceful.
Modely, ktoré dosahujú takúto kvalitu, potom otvárajú niekoľko zaujímavých etických otázok. Dokážu napríklad pomerne úspešne písať články, príspevky na sociálne siete či dokonca viesť konverzáciu. Majú ľudia právo vedieť, že komunikujú so strojom? Aký postoj by mala spoločnosť zaujať ku strojom, ktoré sa na sociálnych sieťach používajú na vedenie rozličných kampaní? Otázkou je tiež ochrana súkromia. Jazykové modely sú často trénované na dátach stiahnutých z webu, ale tieto dáta môžu obsahovať aj súkromné údaje alebo údaje o ľuďoch, ktorí si neželajú, aby sa tieto údaje uchovávali.
V súčasnosti sa vedú práve boje o právo na zabudnutie. Tieto boje bude treba zviesť aj pri jazykových modeloch. Ďalším problémom súvisiacim so spracovaním textu z webu sú rozličné formy asociálneho správania. Text môže obsahovať konšpiračné teórie, rasistické texty, texty podnecujúce k násiliu, klamstvá a akékoľvek ďalšie negatívne javy, ktoré ľudská spoločnosť produkuje. Jazykový model však nevie rozlíšiť hodnotu týchto textov a preberá ich do seba takisto ako akýkoľvek iný text. Pochybné znalosti sa potom môžu pretaviť aj do aplikácií, kde sa takéto jazykové modely používajú.

