


What's

May 13. 2021
Will We Talk with Machines One Day?
A language model is an invisible technology virtually used by every Internet user without really knowing about it. The concept is fairly simple – a model that is able to predict the next word in an incomplete sentence. For instance, if a language model processes “I like cats more than …”, the model can estimate that the next word will most likely be “dogs”. Such a technology has a few obvious and a few less obvious uses.
One of the more obvious uses is to automatically predict and insert words while typing, commonly seen on mobile phones. Even if the user made a few typos, the language model can infer the actual word the user intended to type. Speech-to-text, another feature widely present on phones, leverages the language model in a similar way. Even if the user’s speech is not completely intelligible — which may happen, for instance, in the middle of a noisy street — the language model can predict the next word that the user was about to utter.
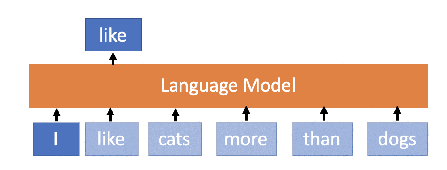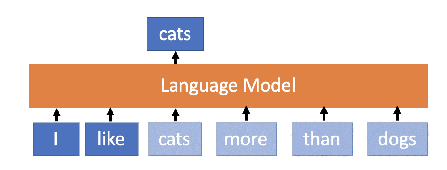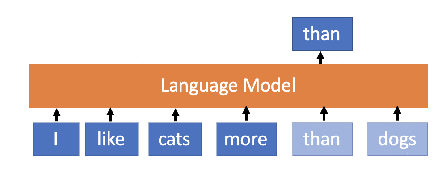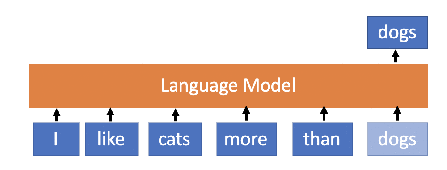
Apart from the aforementioned uses, numerous other applications of language models can be found in the field of natural language processing, such as machine translation (e.g. Google Translate), information retrieval (Google Search), spelling checker (Microsoft Office Word) and many more. The amount of text mankind produces daily has risen dramatically and is often processed and analyzed automatically. The processing also involves the use of language models. Apart from the prediction itself, changes in the internal state of the language models are also observed — when the models react to incoming words, we may infer additional knowledge about the text based on the changes in the models. This concept is closely related to the fact that recent language models are predominantly realized as neural networks — machine learning models inspired by biological neural networks.
It is the progress in this area in recent years that has seen rapid improvements in language models. First, a network of neurons is created — the largest of which having billions of neurons — and such a network is then trained on a text corpus, giving the network a sense of what sentences can be created. As the Web evolved and expanded, so did the corpora, and the current language models are able to process hundreds of gigabytes of text data that they use to learn about languages. Such a scale is currently possible only for the English and probably also the Chinese language. An interesting thing to note is that the models become extremely accurate with enlarged scale and the data they learn from. It is certainly not uncommon nowadays for a human failing to recognize that a text was generated by a computer rather than a human. The current language models create grammatically correct sentences, are able to answer questions and possess a wide array of facts about the world.
Recently, a model named GPT-3, developed by OpenAI, has sparked enormous interest. This huge model was even able to write a column for The Guardian. One user applied this model on the Reddit social network, attempting to produce answers to other users’ questions. You can judge the answer yourself:
Reddit question: Elevator-maintenance folks, what is the weirdest thing you have found at the bottom of the elevator chamber?
GPT-3 answer: The first thing that comes to mind is the recent discovery of a colony of humans living in the shafts and elevator machinery at the bottom of buildings. This was an extraordinary find for sociologists and anthropologists, revealing more about human culture than had ever been possible before. The discovery was made when an elevator repair worker at a building in Washington DC tripped over a shoe that had fallen between the walls of the shaft. The emergency stop button was pressed and the broken machinery triggered a shutdown across all elevators within two city blocks, trapping hundreds of people for hours.
In the investigation that followed it was found that hundreds of people had been living in the elevator shafts and maintenance tunnels for over a decade, making homes out of discarded machinery. As it turns out, the people who lived in these shafts and tunnels were homeless. Many of them had been living on the streets for decades, surviving by scavenging from dumpsters and sleeping under bridges. When the construction of the housing bubble began, these homeless people were forced out to make way for new buildings. But since they had nowhere else to go, and so many of them were desperate for shelter, they found a place in the elevator machinery. I have seen footage of the shafts where they lived, and it is truly an extraordinary sight. I had no idea that humans could be so resourceful.
Models achieving such quality open up a handful of intriguing ethical questions, given how relatively successfully they fare in writing articles, posting on social networks or even leading a conversation. Do people have the right to know they are communicating with a machine? How should the society approach machines that are being used to lead various campaigns on social networks? This is especially delicate for political matters. Privacy protection is another question. Language models are often trained on data collected from the Web, but such data may also contain sensitive, personal information or information about people who do not wish these data to be stored.
Nowadays, the right to be forgotten is being fought for — and we should definitely not omit language models from this fight. Another problem associated with text processing on the Web are various forms of antisocial behavior. Text may contain conspiracy theories, racist remarks, text inciting violence, false claims and other negative phenomena the society produces. However, a language model cannot distinguish the value of these texts and processes them as any other kind of text. Dubious knowledge may then be carried over to applications leveraging these models.

