


Čo je

aug 16. 2022
Komponenty a vlastnosti dobrých vysvetlení rozhodnutí modelov umelej inteligencie
Vysvetliteľná umelá inteligencia: od čiernych skriniek k transparentným modelom
Z pohľadu strojového učenia (angl. Machine learning, ML) žijeme šťastné časy. Pre mnohé úlohy, ktoré sme doteraz nevedeli s pomocou umelej inteligencie uspokojivo vyriešiť, poznáme nie jednu, ale mnoho rôznych ML metód alebo modelov, z ktorých si môžeme vybrať a dosiahnuť aspoň akceptovateľné výsledky. Toto množstvo modelov, spôsobov spracovania dát, ich variácií a možných kombinácií predstavuje výzvu – musíme nájsť takú konfiguráciu, ktorá vyhovuje našej úlohe a dátam.
Aby sme našli správny model, musíme definovať kritériá, ktoré merajú, ako dobre konkrétny model a jeho parametre a hyperparametre adresujú daný problém. Často používanými kritériami sú (v závislosti od úlohy) napríklad presnosť, správnosť, úplnosť, F1 skóre alebo kvadratická chyba.
V ďalšom kroku zvyčajne vykonáme optimalizáciu tzv. hyperparametrov. Tu sa snažíme nájsť dobrú konfiguráciu modelu (napríklad architektúru neurónovej siete) a postupnosť krokov predspracovania a následného spracovania dát. Ak máme k dispozícii dostatočné prostriedky, môžeme dokonca využiť automatizované strojové učenie (angl. Automated ML alebo AutoML), prostredníctvom ktorého môžeme nájsť vhodnú konfiguráciu v priestore všetkých dostupných konfigurácií plne automaticky.
Vďaka pozornosti, ktorá je v posledných rokoch venovaná vysvetliteľnému strojovému učeniu, sa stal počet metód vysvetliteľnosti podobne ohromujúci ako počet rôznych metód strojového učenia. Ak chceme napríklad poskytnúť používateľom dobré vysvetlenia rozhodnutí komplexného modelu, musíme nájsť nielen správnu metódu vysvetliteľnosti ako takú, ale aj jej konkrétnu konfiguráciu.
Aby sme takúto konfiguráciu našli, môžeme si požičať niektoré koncepty z AutoML. Podobne ako v AutoML, na vstupe máme priestor dostupných metód a ich konfigurácií. Na výstupe chceme dostať takú kombináciu metódy a konfigurácie, ktorá nám bude poskytovať dobré vysvetlenia pre našu kombináciu úlohy, modelu a dát. V takomto prípade môžeme hovoriť o automatizovanej vysvetliteľnej umelej inteligencii alebo AutoXAI.

Náročnou časťou AutoXAI je zadefinovať, ako porovnávať rôzne metódy vysvetliteľnosti. Inými slovami – čo to znamená “dobré vysvetlenie”?
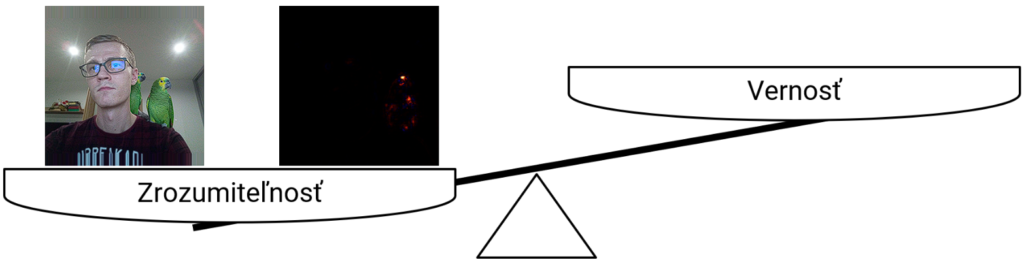
Dobré vysvetlenie vyvažuje dva komponenty – zrozumiteľnosť a vernosť
Podľa viacerých autorov (napr. [1, 2]) by dobré vysvetlenie malo byť v rovnováhe medzi dvoma komponentmi. Malo by verne opisovať správanie modelu (vernosť, angl. fidelity) a malo by byť zrozumiteľné pre ľudí (angl. understandability).
Ak je vysvetlenie zrozumiteľné, ale chýba mu vernosť, mohli by sme skončiť s vysvetleniami, ktoré vyzerajú “dobre” alebo tak, ako by si to človek predstavoval, ale nemusia správne opisovať rozhodovací proces modelu. Znamená to, že vysvetlenie napríklad nemusí byť úplné. Môže v ňom chýbať informácia o tom, že nejaká časť vstupných dát významne ovplyvnila rozhodnutie modelu strojového učenia. Príklad môžete vidieť na Obrázku 2.
Na druhej strane, ak vysvetleniu chýba zrozumiteľnosť, môže používateľa zahltiť nadbytočnými informáciami, alebo môže byť také chaotické, že mu používateľ (človek) nebude rozumieť. Napríklad, ak niektoré časti vstupu mali zanedbateľný vplyv na výslednú predikciu modelu, môže byť kontraproduktívne zahrnúť takúto informáciu do vysvetlenia, ktoré je poskytnuté človeku. Príklad vysvetlenia vo forme teplotnej mapy, ktorá zvýrazňuje aj pixely obrázku, ktoré mali iba minimálny vplyv na predikciu, môžete vidieť na Obrázku 3.

Aby to nebolo také jednoduché, nie vždy platí, že medzi zrozumiteľnosťou a vernosťou musí byť rovnováha. Zvýšenie zrozumiteľnosti môže v skutočnosti viesť k zníženiu vernosti a naopak. Ak chceme napríklad použitiť vysvetlenie na automatizované ladenie modelu (angl. debugging) a identifikáciu chýb v ňom, vernosť vysvetlení bude dôležitejšia ako zrozumiteľnosť.
Bližší pohľad na zrozumiteľnosť a vernosť
Pre jednoduchosť sme sa doteraz obmedzili na dva komponenty vysvetliteľnosti – zrozumiteľnosť a vernosť. Poďme sa teraz pozrieť na jednu z možných taxonómií, inšpirovanú prácami [1, 2], ktorá poskytuje podrobnejší pohľad na vysvetliteľnosť. Ešte detailnejšia taxonómia požiadaviek na vysvetliteľné metódy a systémy a na rámce na ich vyhodnocovanie bola publikovaná autormi Sokol a kol. [3].

Z pohľadu správnosti (angl. soundness) sa pýtame, do akej miery je vysvetlenie pravdivé vzhľadom na model (a dáta), na ktoré sa viaže. Explicitne sa zameriava na to, či vysvetlenie skutočne reflektuje iba správaniu modelu. Vysvetlenie by teda nemalo zavádzať, malo by človeku hovoriť “nič iné, než pravdu”. Niekedy sa pri implementácii metód vysvetliteľnosti, ako napríklad oklúzna analýza, využívajú triky a optimalizácie, vďaka ktorým sú výpočtovo menej náročné. Pri tejto metóde, namiesto toho, aby sme postupne “mazali” časti vstupu jednu po druhej a sledovali dopad na predikciu modelu, zmažeme väčšiu časť vstupu naraz. Môže sa teda stať, že ak naraz vymažeme časť, ktorá mala vplyv na predikciu modelu a aj takú, ktorá vplyv nemala, finálne vysvetlenie o oboch týchto častiach povie, že významne ovplyvnili predikciu.
Kompletnosť (angl. completeness) opisuje kvalitu vysvetlení z hľadiska toho, aká časť celého rozhodovacieho procesu a dynamiky modelu je zachytená daným vysvetlením. Pýtame sa, do akej miery vysvetlenie opisuje celý model (alebo dokonca systém). Chceme, aby nám vysvetlenie hovorilo nielen pravdu, ale “celú pravdu”.
Jasnosť (angl. clarity) hovorí o tom, že vysvetlenie by nemalo byť zmätočné a malo by byť jednoznačné. Okrem toho by pre podobné vstupy, pri ktorých sa aj model samotný rozhodoval podobným spôsobom, mali byť aj vysvetlenia podobné. V opačnom prípade takéto vysvetlenia nebude človek vnímať ako konzistentné.
Šírka (angl. broadness) opisuje, na akú časť úlohy a dát je vysvetlenie možné aplikovať. Ako príklad si uvedieme hlbokú konvolučnú neurónovú sieť, ktorej úlohou je klasifikovať maľby maľované v rôznych štýloch. Od metódy vysvetliteľnosti chceme, aby nám objasnila, prečo konkrétny obraz neurónová sieť zaradila do konkrétneho štýlu. Môže sa stať, že jedna a tá istá metóda vysvetliteľnosti bude schopná poskytnúť zmysluplné vysvetlenie len pre určitú skupinu obrazov. Napríklad, pri moderných obrazoch, ktoré sa skladajú len zo základných geometrických tvarov, bude zdôvodnenie také, že sa na obraze nachádza veľké množstvo trojuholníkov, štvorcov či kruhov a žiadne iné tvary. Naopak, pri veľmi abstraktných dielach (napríklad na štýl Jacksona Pollocka) nebude metóda schopná poskytnúť žiadne zmysluplné vysvetlenie.
Na úspornosť (angl. parsimony) sa vieme pozerať ako na aplikáciu princípu Occamovej britvy. Ako sme ukázali na príklade vyššie, vysvetlenie by z pohľadu zrozumiteľnosti malo obsahovať len tie detaily, ktoré prinášajú adresátovi (človeku) nejakú hodnotu. Malo by byť také jednoduché, ako je to len možné. Ak má vysvetlenie formu vety v prirodzenom jazyku, táto veta by nemala obsahovať zbytočnú vatu. Napríklad, lepším vysvetlením toho, prečo model klasifikoval aktivitu na obrázku ako “varenie”, je veta “na obrázku je muž v zástere a drží v ruke varechu” a nie veta “na obrázku je starší muž so šedivými vlasmi, v ruke drží vyrezávanú varechu hnedej farby, hodiny na stene ukazujú 11 hodín a na stole sú kvety”.
Záver
V tejto časti nášho seriálu o vysvetliteľnej umelej inteligencii sme sa pozreli, aké komponenty a vlastnosti by malo mať dobré vysvetlenie.
Ukázali sme si, že dobré vysvetlenie by malo vyvažovať zrozumiteľnosť a vernosť. Musí byť pochopiteľné pre človeka a zároveň musí verne opisovať skutočné správanie modelu, ktorého predikcie vysvetľuje.
Dosiahnuť rovnováhu medzi zrozumiteľnosťou a vernosťou pritom nie je jednoduchá úloha, pretože zvýšenie niektorej z vlastností zrozumiteľnosti môže zároveň znížiť vernosť a naopak. Zároveň platí, že záleží od konkrétnej úlohy, či chceme mať vysvetlenia viac zrozumiteľné, alebo či, chceme, aby boli veľmi detailné a pokrývali všetky detaily rozhodovacieho procesu modelu strojového učenia.
V ďalšej časti seriálu si ukážeme dve rodiny prístupov a príklady konkrétnych metrík, ktorými môžeme merať kvalitu vysvetlení z pohľadu vlastností, ktoré sme si v tomto článku popísali.
Projekt podporil Nadačný fond PricewaterhouseCoopers v Nadácii Pontis.
Referencie
[1] ZHOU, Jianlong, et al. Evaluating the quality of machine learning explanations: A survey on methods and metrics. Electronics, 2021.
[2] MARKUS, Aniek F.; KORS, Jan A.; RIJNBEEK, Peter R. The role of explainability in creating trustworthy artificial intelligence for health care: a comprehensive survey of the terminology, design choices, and evaluation strategies. Journal of Biomedical Informatics, 2021.
[3] SOKOL, Kacper; FLACH, Peter. Explainability fact sheets: a framework for systematic assessment of explainable approaches. In: Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency. 2020.





