Čo je

jún 11. 2025
Fact-Check Retrieval Using Text Embedding Models
In the age of viral misinformation, professional fact-checkers face a growing challenge: there is simply too much content to sift through, and misinformation is spreading faster than ever. In these circumstances, we need to make sure that fact-checkers join forces to the greatest extent possible – wasting effort by duplicating work is something that we can simply no longer afford.
To help fact-checkers reduce duplicate effort, we should ensure that whenever they are faced with a suspicious claim, they can quickly look up whether it has already been fact-checked and where. There are three aspects to this kind of search (document retrieval), which are not well-addressed by generic search engines: the search (i) needs to be limited only to reliable fact-checking portals; (ii) needs to be cross-lingual (i.e. support search across different languages); and (iii) needs to be multimodal (combining text and visual content). Thanks to advances in natural language processing (NLP), this is now becoming a reality.
As part of our DisAI AMPLIFIED project, we have now prepared a 3-part blog series on this topic; we will gradually go over:
- Fact-Check Retrieval Using Text Embedding Models, where we explain the fact-check retrieval task and how it can be addressed using text embedding models (TEMs), while supporting search across different languages.
- Fact-Check Retrieval Using LLMs, where we explain how generative large language models (LLMs) enter into the equation and how they can help to refine retrieval to improve results further.
- Multimodal Fact-Check Retrieval, where we explain how visual content can be leveraged to improve retrieval performance, starts with a very straightforward setup based on a combination of several smaller models and then goes on to how generative LLMs can be applied to the same task.
Text Embedding Models vs. Generative LLMs
Before diving into the topic of fact-check retrieval, it will be useful to explain the distinction between two different kinds of models: text embedding models (TEMs) and generative LLMs.
(Text Embedding Models) Text embedding models are (large) language models which transform input text (of variable size) into an embedding vector (a fixed-size sequence of numbers). TEMs can be pre-trained on large quantities of language data using a generic task such as masked language modelling, where you mask a word in a sentence and train the model to guess what it was. This will help them build up representations of natural language; however, they will not be able to do anything else out of the box. To become useful, they need a bit of additional training on a task-specific dataset – then they can become very good at a range of NLP tasks such as sentiment classification, named entity recognition, or question answering.
If you have a huge task-specific dataset, a TEM can also be trained on it directly, foregoing pre-training. For most tasks, this is not the case, but the fact is worth mentioning because retrieval is one of the exceptions, where models are sometimes trained directly.
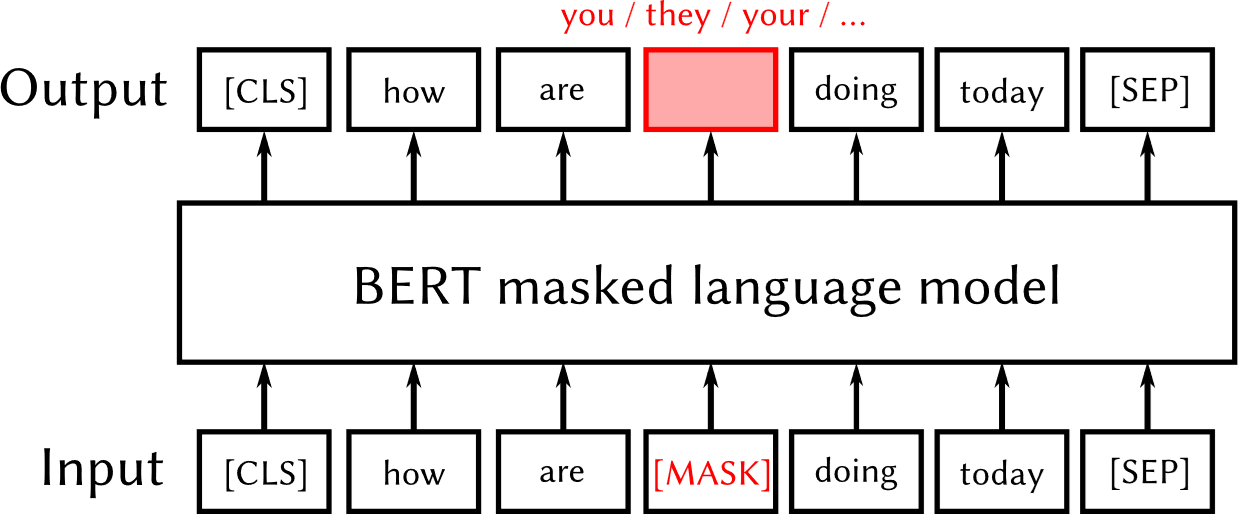
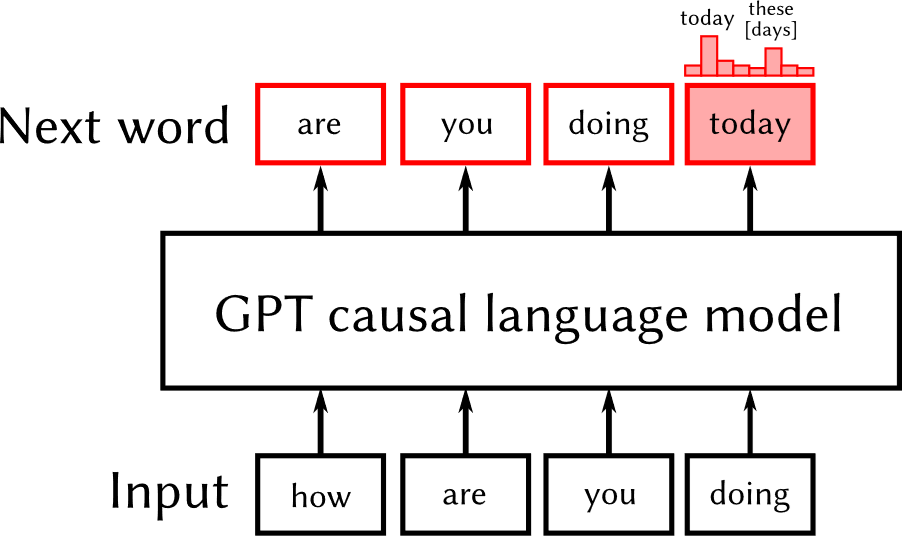
Fig. 1: On the left, a text embedding model; the [CLS] output corresponds to the embedding vector. On the right, a generative LLM predicts probabilities for the next word.
(Generative LLMs) Generative LLMs, on the other hand, are not pre-trained to output an embedding vector, but rather to predict the next word, given some input text. When applied repeatedly, generating one word at a time, they can be used to produce longer texts. Generative LLMs are typically much larger and more expensive to run than their comparable TEM counterparts, but they excel at generating long passages of rich and coherent text.
Crucially, their next-word prediction capabilities make them good at a range of different tasks such as essay writing, question answering, translation, source code generation, etc. They can perform these purely based on natural-language instructions (or a very small number of examples) and without any additional task-specific training. Being larger and trained on vast amounts of text, they typically also acquire a lot of general world knowledge and often exhibit more nuanced understanding (for lack of a better word) of complex texts.
Fact-Check Retrieval Using Text Embedding Models
A straightforward application of TEMs to fact-check retrieval is arguably the simplest way to address the problem, and this is therefore where we are going to start in the first instalment of our blog.
How Retrieval Using TEMs Works
The main idea, as illustrated in Fig. 1, is very simple – we simply feed the query (i.e. what we are looking for) into the TEM to get its embedding vector. Then we do the same for all the candidate documents that we have (these could also be smaller units like individual paragraphs), and we get the embedding vectors for them. Finally, we compare the embedding vector of our query against those of all the documents and rank the documents by the resulting similarity scores. The top-ranked documents should then be the most relevant ones, so we can take, e.g. the top 5 and work with them further.
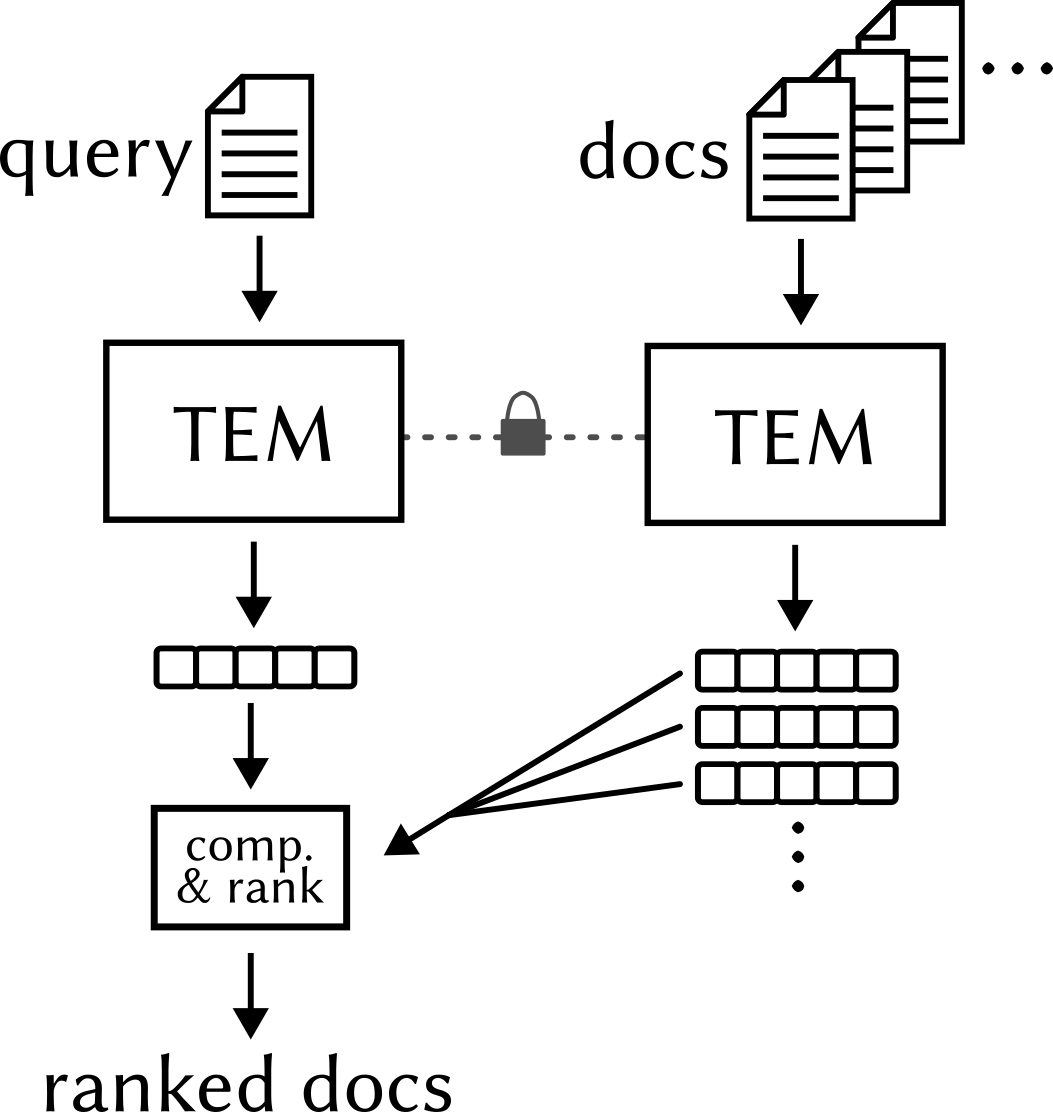
Fig. 2: Document retrieval using text embedding models (TEMs).
How TEMs Are Trained for Retrieval
Next, let’s briefly explore how TEMs are trained for retrieval. We can take one rather well-known retrieval model called E5 as an example. To train the model, the authors collect a lot of textual pairs where both pieces of text in each pair are related somehow. These include, for instance: (i) post, comment pairs from Reddit, (ii) entity name + section title, passage pairs from Wikipedia, (iii) question, upvoted answer pairs from Stackexchange, …
These pairs are then used to train the model contrastively – the TEM is trained to make the embedding vectors of texts:
- As similar to each other as possible for texts which form a pair;
- As different from each other as possible for texts which do not form a pair.
This gives rise to a space such as that illustrated in Fig. 2, where similar items are close to each other.
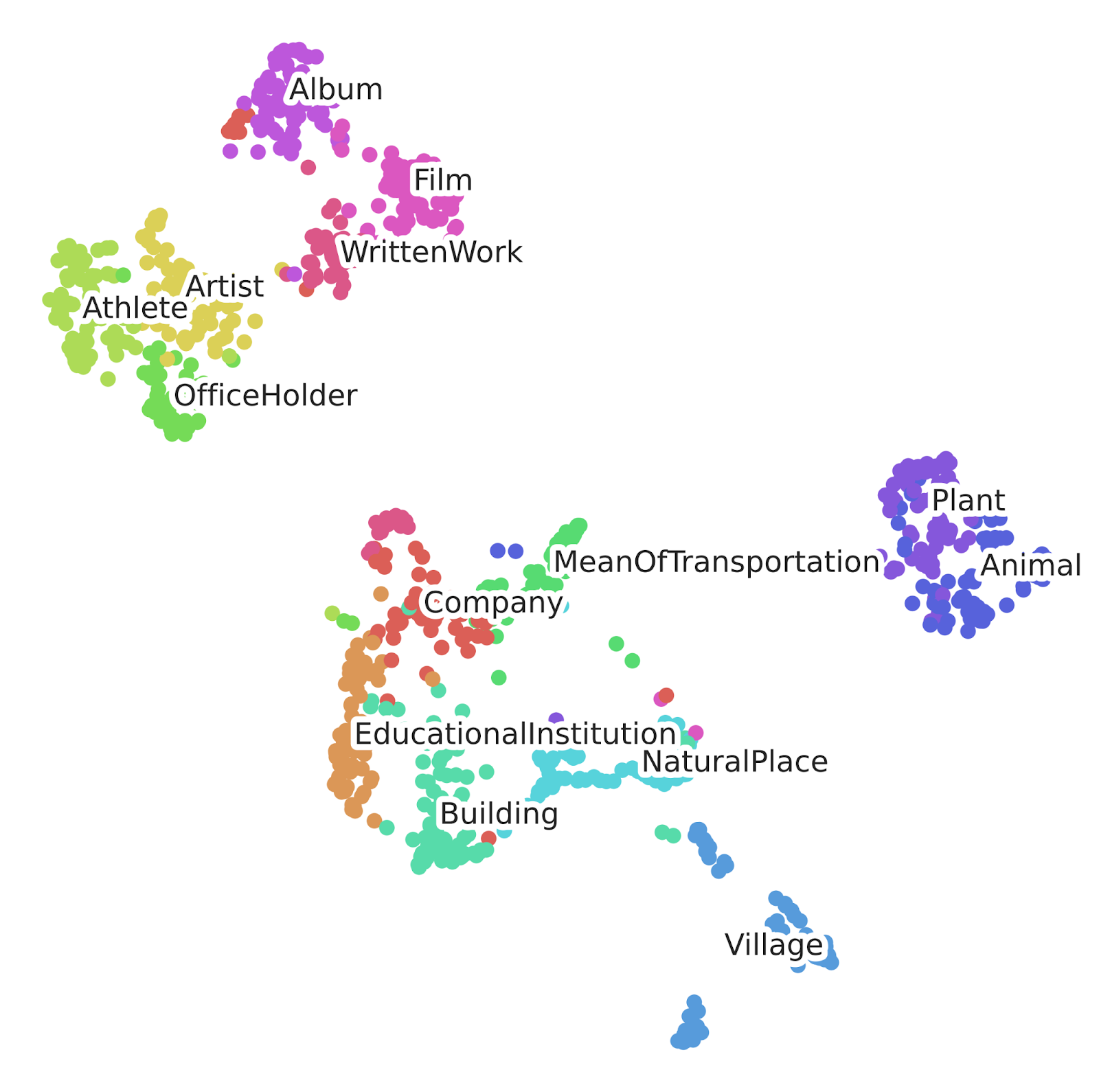
Fig. 3: Vector embeddings from E5 reduced to 2D using a method called UMAP.
(The “fancyzhx/dbpedia_14” dataset from HuggingFace was embedded to create the figure.)
Incidentally, E5 is one of the models that are not pretrained using masked language modelling, but directly trained for retrieval on a very large dataset called “Colossal Clean Text Pairs” (CCPairs).