


Čo je

sep 6. 2021
Cross-Lingual Learning
Matúš Pikuliak je náš najnovší doktorand, ktorý nedávno obhájil titul PhD. Vo svojom výskume sa venoval práve metódam, ktoré by mali preklenúť nerovnosť medzi jazykmi a priniesť užitočné aplikácie ľudom a komunitám, ktoré doteraz nemali možnosť naplno využívať pokrok založený na hlbokom učení vo svojej materinskej reči.
Hlboké učenie v posledných rokoch prinieslo výrazné pokroky v spracovaní prirodzeného jazyka. Strojový preklad, vyhľadávanie informácií, automatický prepis reči do textu a iné aplikácie, ktoré dnes bežne používame, dosiahli práve vďaka hlbokému učeniu výrazne zlepšenie. Podobne ako v iných doménach, aj tu je tento pokrok závislý na zozbieraní dátových množín, z ktorých sa modely strojového učenia učia vykonávať zadanú úlohu. Z rozličných historických, sociologických, technologických a iných príčin sú dnes niektoré jazyky (napr. angličtina, mandarínska čínština) veľmi populárne, ovládajú ich miliardy ľudí a prebieha v ich spracovaní pomocou umelej inteligencie bohatý výskum. Na druhú stranu existujú tisíce jazykov, ktoré sú na okraji záujmu, ovláda ich rádovo menej ľudí, netvoria sa v nich nové texty v takom objeme ako v iných jazykoch. Použitie prístupov umelej inteligencie je v nich častokrát omnoho zložitejšie a niekedy až nemožné, najmä preto, že pre tieto jazyky neexistujú dostatočne veľké dátové množiny.
Matúš je náš najnovší doktorand, ktorý nedávno obhájil titul PhD. Vo svojom výskume sa venoval práve metódam, ktoré by mali preklenúť nerovnosť medzi jazykmi a priniesť užitočné aplikácie ľudom a komunitám, ktoré doteraz nemali možnosť naplno využívať pokrok založený na hlbokom učení vo svojej materinskej reči. Preskúmal možnosti tzv. učenia medzi jazykmi. Ide o paradigmu strojového učenia, kedy sa znalosti a dáta vytvorené v jednom jazyku prenášajú rozličnými technikami do iných jazykov. Napríklad, ak sa umelá inteligencia naučí riešiť problém vyhľadávania informácii v angličtine, snahou týchto techník je preniesť tieto znalosti do iných jazykov tak, aby sme aj v nich vedeli vyhľadávať.
Súčasťou Matúšovej práce bolo vykonanie jednej z vôbec prvých prehľadových štúdií v tejto oblasti a podarilo sa ju publikovať v časopise Expert Systems With Application (v Google Scholar je to časopis zo sekcie Umelá Inteligencia s najvyšším h-indexom). Základom tohto prehľadu bolo zmapovanie doteraz použitých prístupov k učeniu medzi jazykmi, kde sa zanalyzovalo vyše 170 doteraz existujúcich prác. Dôkladná analýza použitých jazykov, datasetov, úloh a prístupov poskytla pohľad na stav oblasti, aký doteraz chýbal. Ukázalo sa, že učenie s prenosom medzi jazykmi je veľmi všestranná technológia, použiteľná na prakticky ľubovoľnú úlohu spracovania prirodzeného jazyka. Ale ukázala sa aj dominancia veľkých európskych jazykov pri experimentálnej práci. Aj napriek tomu, že jedným z hlavných motívov učenia s prenosom medzi jazykmi je pomôcť jazykom s nedostatkom dát, experimentálne overenie sa častokrát vykonáva práve na jazykoch, ktoré takúto pomoc možno ani až tak nepotrebujú. Matúš taktiež prispel k teoretickému porozumeniu takéhoto učenia, keď ho formálne zadefinoval a navrhol rozdelenie existujúcich prístupov podľa druhu znalosti, ktorá slúži na komunikáciu medzi rôznymi jazykmi. Takto sa medzi jazykmi môžu šíriť anotácie vzoriek, črty vzoriek, hodnoty parametrov a vnútorné reprezentácie modelov.
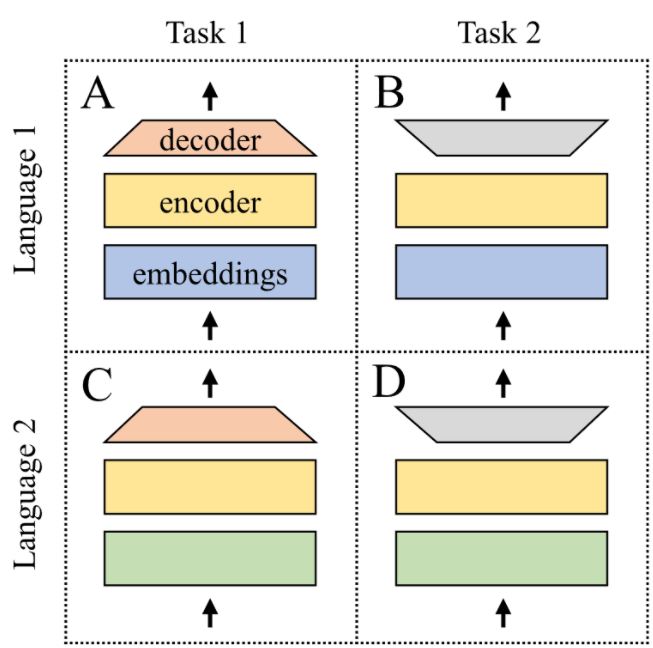
Na základe tejto analýzy stavu oblasti sa potom Matúš v práci venoval kombinácii učenia s prenosom medzi jazykmi a medzi úlohami. Zvykom bolo študovať tieto dva prístupy oddelene. Tu sa Matúš odhodlal skombinovať ich a preskúmať možnosti a limitácie takéhoto spojenia. Experimenty prebiehali s tzv. mriežkou modelov. Každý model mal zadefinovanú konkrétnu úlohu v konkrétnom jazyku a spolu pokrývali všetky možné kombinácie vybraných 4 úloh a 4 jazykov. Modely v takejto mriežke sa učili riešiť úlohu na základe svojich dát. Zároveň sa však učili aj od seba navzájom vďaka mechanizmu, ktorý sa nazýva zdieľanie parametrov. Výsledkom experimentov boli objavy v tom, ako správne kombinovať dáta z rôznych jazykov tak, aby sme maximalizovali výkon modelov v menej skúmaných jazykoch.
Vykonaný výskum má potenciál byť aplikovaný v praxi pri vývoji metód a modelov v “chudobných” jazykoch, kam v niektorých prípadoch patrí aj slovenčina. Prenosom znalostí z bohatých jazykov pomocou navrhnutých metód dokážeme zlepšiť výsledky práve pre tieto jazyky. Tieto technológie už aj dnes pomáhajú ľuďom, verejne strojové prekladače (napr. Google Translate) už takéto techniky používajú a preklady do a z menej rozšírených jazykov sú čoraz lepšie práve vďaka prenosu znalostí. Toto je ďalším krokom v pokračujúcej demokratizácii umelej inteligencie a informačných technológií vo všeobecnosti. Práca s viacerými jazykmi sa navyše ukazuje ako zaujímavá výzva aj pre ďalšie aktivity KInIT-u, kde dokážeme podobné techniky použiť aj v našich existujúcich projektoch zameraných napr. na boj proti dezinformáciam alebo v rôznych výskumných projektoch našich partnerov.
Výber z Matúšových publikácií:
1. Pikuliak, M., Šimko, M., & Bielikova, M. (2021). Cross-lingual learning for text processing: A survey. Expert Systems with Applications, 165, 113765.
2. Pikuliak, M., Simko, M., & Bielikova, M. (2019, January). Towards combining multitask and multilingual learning. In International Conference on Current Trends in Theory and Practice of Informatics (pp. 435-446). Springer, Cham.

