


Čo je

sep 26. 2022
Ako merať kvalitu vysvetlenia predpovede umelej inteligencie?
Vysvetliteľná umelá inteligencia: od čiernych skriniek k transparentným modelom
V minulej časti seriálu sme sa pozreli na to, aké komponenty a vlastnosti by mali mať dobré vysvetlenia. Prvý komponent, zrozumiteľnosť, sa zameriava na to, do akej miery sú vysvetlenia rozhodnutí a správania modelov strojového učenia a umelej inteligencie zrozumiteľné pre človeka. Dokáže ich človek kognitívne uchopiť?
Druhý komponent, vernosť, hovorí, do akej miery vysvetlenia opisujú skutočné správanie modelu, alebo celého systému.

Zadefinovanie toho, aké vlastnosti by malo mať dobré vysvetlenie, je dôležitým prvým krokom k tomu, aby sme ich dosiahli. Vieme, čo chceme dosiahnuť – na vstupe máme model strojového učenia alebo umelej inteligencie (napr. neurónovú sieť), vstup (napr. obrázok), predpoveď, ktorú pre tento vstup model predikoval a napokon vysvetlenie. Na výstupe chceme určiť, ako zrozumiteľné a verné toto vysvetlenie je. Otázka je – akým spôsobom vieme zmerať kvalitu vysvetlení? (Obrázok 1)
Na vyhodnocovanie kvality vysvetlení rozlišujeme dve rodiny prístupov: vyhodnocovanie zamerané na človeka a vyhodnocovanie zamerané na funkcionalitu (Obrázok 2). V tomto článku si na konkrétnych príkladoch predstavíme vyhodnocovanie zamerané na človeka. V nasledujúcom článku sa budeme venovať vyhodnocovaniu zamerané na funkcionalitu.
Pri vyhodnocovaní zameranom na človeka vychádzame z predpokladu, že adresátom vysvetlení je človek a je preto potrebné zapojiť do procesu vyhodnocovania ľudí. Pri vyhodnocovaní zameranom na funkcionalitu je zas cieľom kvantitatívne a automatizované vyhodnotenie kvality vysvetlení.

Vyhodnocovanie kvality vysvetlení zamerané na človeka
Jedným z najdôležitejších cieľov výskumu v oblasti vysvetliteľnej umelej inteligencie ja zvýšiť transparentnosť netransparentných, komplexných modelov a ich predikcíí. Takýmto spôsobom je možné zvýšiť mieru, do akej ľudia akceptujú riešenia založené na umelej inteligencii v praxi. Taktiež môže poskytnúť ľuďom nástroje na kontrolu umelej inteligencie (napr. ak by vysvetlenie predikcie bolo evidentne nelogické, človek by to mal brať do úvahy).
Pri vyhodnocovaní kvality vysvetlení zameranom na človeka je hlavná myšlienka jednoduchá – použiť ľudí, ktorým sú vysvetlenia adresované, na vyhodnotenie ich kvality. Pozeráme sa pritom na dva aspekty – ako vysvetlenia pomáhajú ľuďom plniť rôzne úlohy a ako ľudia vnímajú vysvetlenia. Vo svojej práci Zhou a kol. hovoria o vyhodnocovaní založenom na aplikácii (angl. application-grounded) a vyhodnocovaní založenom na ľuďoch (angl. human-grounded) [1].
Z pohľadu vyhodnocovania založeného na aplikácii nás zaujíma, ako veľmi a či vôbec dokážu vysvetlenia pomôcť používateľom pri plnení rôznych úloh. Zväčša porovnávame rôzne metriky výkonnosti, efektívnosti či komfortu dvoch skupín používateľov, ktorí plnia tú istú úlohu. Používatelia zo skupiny A majú k dispozícii iba predikciu modelu, používatelia zo skupiny B majú k dispozícii aj nejakú formu vysvetlenia.
Pri vyhodnocovaní založenom na ľuďoch sa zameriavame na to, ako vnímali poskytnuté vysvetlenia samotní používatelia.
Vzorový príklad, kvantitatívne a kvalitatívne metriky
Pozrime sa na jednoduchý príklad – blogovaciu platformu. Jednou z úloh administrátora takejto platformy je identifikovať a prípadne mazať nenávistné príspevky, ktoré sa na platforme vyskytnú. Ak sa jedná o blog, na ktorý denne pribudnú desiatky alebo stovky tisíc príspevkov, nie je v silách jedného administrátora skontrolovať ich všetky. Prirodzeným riešením je využiť detektor nenávistných prejavoch založený na strojovom spracovaní prirodzeného jazyka, ktorý identifikuje potenciálne nenávistné príspevky. Počet príspevkov, ktoré musí administrátor skontrolovať, sa tak rapídne zníži. Stále ich však môžu byť tisícky denne. Otázkou je, akým spôsobom vie vysvetliteľná umelá inteligencia pomôcť ešte viac zefektívniť prácu administrátora?
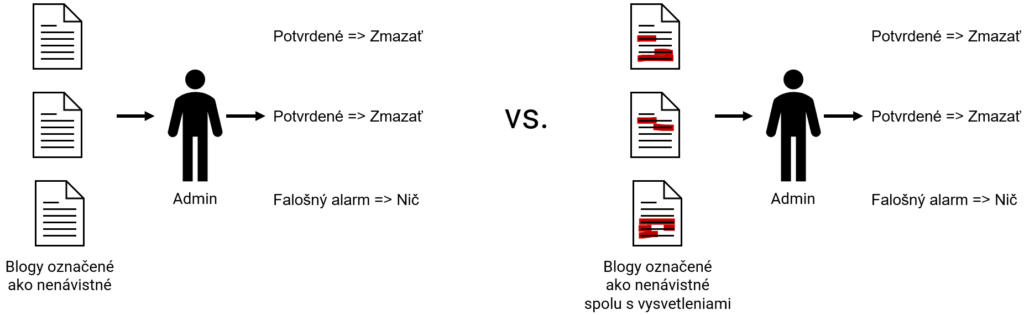
Na Obrázku 3 vidíme porovnanie dvoch situácií. V prvom prípade má administrátor k dispozicii iba samotné príspevky, ktoré umelá inteligencia identifikovala ako nenávistné. V druhom prípade sú v textoch príspevkov zvýraznené tie časti, ktoré umelú inteligenciu presvedčili, že sa jedná o nenávistné príspevky. Keďže administrátor nemôže len tak zmazať príspevok, ktorý neporušil pravidlá blogu (platí sloboda slova), musí príspevky identifikované umelou inteligenciou skontrolovať.
V prvom prípade musí skontrolovať celé texty, až kým nenarazí na nenávistný prejav (potvrdený nenávistný prejav), alebo kým prečíta celý text a usúdi, že sa jedná o falošný poplach a príspevok je v poriadku.
V druhom prípade, kedy má administrátor k dispozícii aj vysvetlenia, sa môže primárne zamerať na zvýraznené časti textov, čo môže významne zefektívniť jeho prácu. Najmä ak sa jedná o skutočne nenávistný príspevok a nie falošný poplach. V tom prípade stačí, aby sa napr. rasistický alebo antisemitský výrok vyskytol raz, vďaka čomu sa administrátor nemusí ďalej zaoberať zvyškom textu a rovno môže príspevok skryť, zmazať alebo vyzvať autora na korekciu. Týmto sa významne uľahčí a zrýchli práca administrátora.
Spôsob kvantitatívneho merania kvality vysvetlení závisí od úlohy. Iným spôsobom budeme merať výkonnosť používateľov systému určeného na detekciu nenávistných príspevkov a iným používateľov systému na počítanie rakovinových buniek v histologických snímkach. V príklade s blogovacou platformou by bolo vhodné merať napríklad:
- Rozdiel v počte príspevkov (efektívnosť), ktoré sú schopní skontrolovať administrátori, ktorí nemajú k dispozícii vysvetlenie a ktorí majú.
- Rozdiel v presnosti, ktorú dosiahnu administrátori z jednej alebo druhej skupiny.
- Rozdiel v schopnosti odhaliť nesprávnu predikciu modelu.
Veľkou výhodou kvantitatívneho merania je jeho objektívnosť. Pri správne nastavenom experimente (vyvážené skupiny používateľov, rovnaké podmienky, atď.) dokážeme s pomerne veľkou istotou povedať, či a aký veľký prínos mali poskytnuté vysvetlenia.
Pri kvalitatívnom meraní sa viac zameriavame na subjektívne hodnotenie prínosu a spokojnosti používateľov s vysvetleniami. Častou formou získavania spätnej väzby sú dotazníky, v ktorých používatelia hodnotia vysvetlenia z rôznych uhlov pohľadu, napr.:
- Užitočnosť – základný pohľad na to, či vôbec používatelia pokladajú poskytnuté vysvetlenie za užitočné.
- Spokojnosť.
- Zrozumiteľnosť.
- Istota a dôvera – do akej miery používatelia veria, že vysvetlenia, ktoré dostali, sú správne. V predchádzajúcom dieli sme si povedali, že vysvetlenia by mali byť konzistentné, v opačnom prípade im človek nebude dôverovať.
Napriek tomu, že kvalitatívne meranie je do veľkej miery subjektívne, jedná sa o dôležitú súčasť vyhodnocovania metód vysvetliteľnosti. Sú to totiž používatelia (ľudia), ktorí sú adresátmi vysvetlení a preto je nutné merať aj ich subjektívny postoj k nim. Ak by napríklad vysvetlenie pomohlo používateľovi dosiahnuť vyššiu presnosť pri plnení úlohy, no bol by z neho frustrovaný (napr. by bolo príliš rozsiahle), nebolo by to optimálne.
Výhody a nevýhody vyhodnocovania kvality vysvetlení zameraného na človeka
Výhodou vyhodnocovania zameraného na človeka je, že prostredníctvom neho vieme priamo zmerať, aký benefit z vysvetlení majú samotní používatelia. Vieme získať presvedčivý dôkaz o tom, do akej miery sú ľudia s vysvetleniami spokojní a ako veľmi im pomáhajú pri plnení rôznych úloh.
Vďaka tomu vieme používateľovi poskytnúť také vysvetlenie, ktoré je mu “šité na mieru” a ktoré v dostatočnej miere napĺňa vlastnosti, ktoré by dobré vysvetlenie malo mať (môžete ich nájsť v predošlej časti nášho seriálu).
V práci, ktorú tento rok publikovali Tompkins a kol. [2] na Workshope o vysvetliteľnej umelej inteligencii na konferencii IJCAI, sa ukázalo, aké dôležité je validovať rôzne formy a variácie vysvetlení, ktoré dostane používateľ k dispozícii. Napríklad, na prvé počutie dáva zmysel, že čím rozsiahlejšie a kompletnejšie vysvetlenie má používateľ k dispozícii, tým viac by mu malo pomôcť pri plnení danej úlohy. Pri jednom z experimentov s 208 účastníkmi autori porovnávali, aké výsledky dosiahnu účastníci, ktorým budú poskytnuté rôzne počty tzv. “counterfactual” (protichodných) vysvetlení. Ukázalo sa, že menej rozsiahle vysvetlenie (1 alebo 2 “counterfactuals”) bolo pre používateľov objektívne prínosnejšie. Okrem toho samotní používatelia vyjadrili preferenciu dostávať menej vysvetlení.
Potenciálnou nevýhodou vyhodnocovania zameraného na človeka je subjektivita a s tým spojená citlivosť vyhodnocovania a jeho výsledkov na výber ľudí, ktorí sú do vyhodnocovania zapojení. Obzvlášť v prípade, že chceme do experimentu zapojiť väčší počet ľudí, môže byť problém nájsť dostatočný počet dostatočne rozmanitých koncových používateľov. Napríklad počet rádiológov, s ktorými by sme chceli testovať prínos vysvetlení v diagnostickom softvéri podporovanom umelou inteligenciou, je veľmi obmedzený a ich čas je vzácny. Preto sme často odkázaní na vyhodnocovanie s menšou vzorkou koncových používateľov alebo na testovanie s laikmi (v tomto prípade nemusíme byť vôbec schopní vykonať vyhodnocovanie založené na aplikácii).
Ako sme si ukázali v predošlej časti seriálu, dobré vysvetlenie vyvažuje dva komponenty – zrozumiteľnosť a vernosť. Pri tomto type vyhodnocovania sme schopní priamo merať zrozumiteľnosť vysvetlení (je to jedna z otázok, ktorú môžeme používateľovi položiť priamo v dotazníku), no vernosť vieme merať iba nepriamo. Vychádzame totiž z predpokladu, že model je príliš komplexný na to, aby človek úplne pochopil jeho vnútorné správanie a spôsob, akým dospel k predpovedi. Nevie teda ani povedať, či vysvetlenie plne korešponduje so skutočným správaním modelu.
Ďalším problémom je náročnosť takéhoto vyhodnocovania na čas a zdroje. Súčasný výskum vo vysvetliteľnej umelej inteligencii neustále prináša nové prístupy a metódy. Zároveň platí, že vysvetlenie by malo byť špecificky šité na mieru danej úlohe a modelu (a dátam). Ak by sme však chceli vyhodnotiť, ktorá z mnohých metód vysvetliteľnosti a ich rôznych kombinácií najviac pomôže používateľovi pri riešení danej úlohy a ktorú bude používateľ považovať za najlepšiu, museli by sme pre každú úlohu vykonať veľké množstvo experimentov s ľuďmi. Toto nie je reálne uskutočniteľné.
Odpoveďou na problém škálovania, subjektivitu a absenciu priameho merania vernosti vysvetlení prináša vyhodnocovanie kvality vysvetlení zamerané na funkcionalitu. O tejto rodine prístupov si povieme v nasledujúcej časti seriálu.
Záver
V tejto časti nášho seriálu o vysvetliteľnej umelej inteligencii sme sa pozreli na dve základné rodiny spôsobov vyhodnocovania kvality vysvetlení. Bližší pohľad sme venovali vyhodnocovaniu kvality zameranému na človeka.
Na modelovom príklade, v ktorom mali administrátori blogovacej platformy za úlohu bojovať s nenávistnými príspevkami, sme si ukázali, že kvalitu vysvetlení meriame dvomi spôsobmi – kvantitatívne a kvalitatívne.
Pri vyhodnocovaní kvality vysvetlení zameranom na človeka sa sústredíme na dve veci:
- Ako a či vôbec poskytnuté vysvetlenie pomáha človeku pri plnení danej úlohy?
- Ako (subjektívne) vysvetlenie vníma človek?
V prvom prípade typicky kvantitatívne meriame, či sa skupine používateľov, ktorí majú k dispozícii vysvetlenie, darí plniť úlohu lepšie ako tým, ktorí vysvetlenie nemajú. Alternatívne je možné porovnať skupiny používateľov, ktorí dostali rôzne vysvetlenia.
V druhom prípade najčastejšie zbierame spätnú väzbu prostredníctvom dotazníkov, v ktorých zisťujeme napríklad to, do akej miery používatelia považovali vysvetlenia za užitočné alebo zrozumiteľné.
V ďalšej časti seriálu sa pozrieme na vyhodnocovanie kvality vysvetlení zamerané na funkcionalitu, ktoré vhodne dopĺňa vyhodnocovanie zamerané na človeka a adresuje niektoré jeho nevýhody.
Projekt podporil Nadačný fond PricewaterhouseCoopers v Nadácii Pontis.
Referencie
[1] ZHOU, Jianlong, et al. Evaluating the quality of machine learning explanations: A survey on methods and metrics. Electronics, 2021, 10.5: 593.
[2] TOMPKINS, Rick, et al. The Effect of Diversity in Counterfactual Machine Learning Explanations. (2022). IJCAI 2022: Workshop on Explainable Artificial Intelligence (XAI). website: https://sites.google.com/view/xai2022







