


What's



Sep 27. 2023
Are the explanations we consider to be good really good?
Explainable Artificial Intelligence: From Black Boxes to Transparent Models
In previous articles, we introduced three very interesting concepts from the field of eXplainable Artificial Intelligence (XAI):
In this article, we build on these concepts and show one way to not only get good explanations, but also to verify how well different explanations help real humans to accomplish their tasks.
Properties of good explanations
Let’s remind ourselves that, as in machine learning and artificial intelligence, in explainable AI there is a large number of algorithms that the user can use.
If the user is to make an informed choice of the right algorithm, we need a mechanism that allows us to compare different algorithms. In other words, we need to be able to measure which explanations are better and which are worse in the context of the given task and from the perspective of the criteria set by the user.
Before we start with the measurement itself, let’s focus on WHAT we are going to measure – what properties should good explanations have?
At the first level, we say that a good explanation should balance two components – understandability and fidelity:
- Understandability quantifies to what extent the users are able to understand the explanation. For example, whether it does not contain too much irrelevant information and whether it does not overwhelm them.
- Fidelity tells how well the explanation describes the actual behavior and decision-making process of the model. For example, if the explanation tells us that the sentiment of the sentence “Today the weather is nice” was determined by the model to be positive mainly because of the word “nice”, the fidelity measures whether this was really the case and whether the model did not actually decide according to another word in the sentence.
We can, of course, go deeper when exploring the quality of explanations. Each of the components can be divided into different properties that describe different aspects. For more information, please refer to our previous article.
Measuring the quality of explanations: human-centered and functionality-grounded evaluation
Now that we know what properties a good explanation should have, we can focus on the question of how we can measure these properties.
We distinguish two families of approaches to the evaluation of the quality of explanations: Human-centered and functionality-grounded evaluation (Figure 1).

In human-centered evaluation, we start from the assumption that the addressee of the explanations is a human being and it is therefore necessary to involve people in the evaluation process. In functionality-grounded evaluation, the goal is quantitative and automated evaluation of the quality of explanations, most often through the so-called proxy metrics.
Both types of evaluation have their irreplaceable role and complement each other very well. Functionality-grounded evaluation can be used to optimize the explainable AI algorithm itself (so that it produces the best possible explanations). However, if we do not combine it with human-centered evaluation, we cannot reliably answer the most important question – to what extent do explanations help people in fulfilling their tasks?
For more information on measuring the quality of explanations, please refer to our previous article.
How to verify if the seemingly best explanations will be the most helpful ones for users
Imagine that you became fed up with how easily disinformation of all kinds spreads on social media (not difficult to imagine, we believe). That’s why you woke up one day and decided to create your own social network where harmful disinformation will be actively fought.
Success! After a short time, the number of users of your network exceeded the first million. However, as the number of users grew, so did the attractiveness of your network for those you decided to fight against – the people who spread disinformation deliberately.
Despite the fact that you have anticipated this and have trained several administrators in advance to check whether any of the posts are intentionally spreading disinformation, the amount of misinformation is so huge that you manage to check only a fraction of it.
Iteration 1: Let’s help administrators with AI
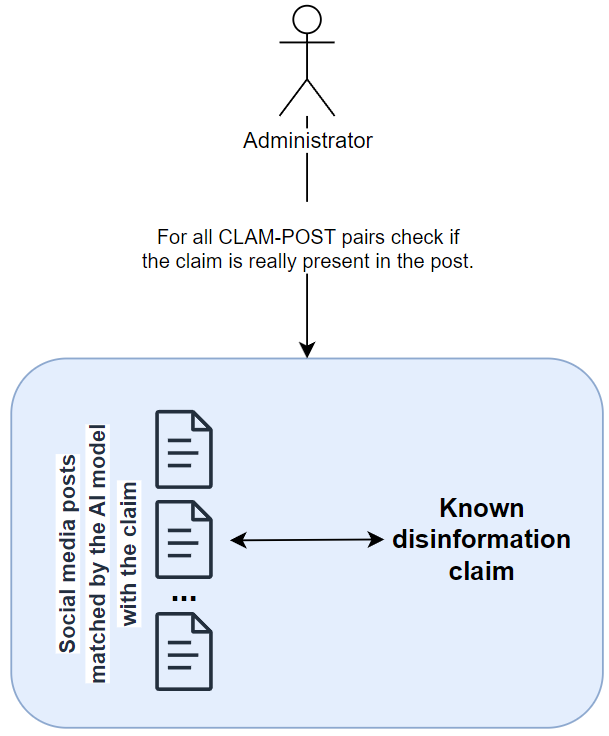
You decide to help your administrators by creating a machine learning tool for them. This tool has a database of the most up-to-date disinformation that is spreading in the public space. The tool continuously checks whether any of the posts contain this or that disinformation.
Instead of reading every single post, admins now only get a filtered list of posts that appear to contain some of the known disinformation claims. It is the administrator’s job to review each of these posts and decide whether a post should be hidden or not. This check is very important, because it is necessary to make sure that the post is really harmful and violates the rules of the social network, since we have the freedom of speech.
Iteration 2: Let’s help administrators with explainable AI
Such a tool saves administrators a significant amount of time. But maybe we can achieve even more with explainable AI.
The problem with the first solution is that some posts can be very long and the disinformation claim, if present, may be hidden at the very end. In addition, disinformation can only form a very small part of the entire post (often deliberately) and look different from the original disinformation claim (use of paraphrasing). Therefore, administrators often have to read the entire post to determine whether or not a given claim is in it. It’s time for another iteration.
This time, you will not only show the selected posts to the administrators, but at the same time you will highlight specific (short) parts in the posts that the AI model evaluated as disinformation. So you make use of explainable AI so that the model tells you not only WHAT (“this post contains disinformation X”), but also WHY (“disinformation X is at the end of the second paragraph”). Your hypothesis is that now the admins will have to read significantly less text and will have time to review more posts, which will lead to the cultivation of discussion.

But when you open the documentation of one of the popular libraries that implement many explainable AI algorithms (e.g., Captum), you will find that there is a large number of such algorithms. So which algorithm will be the best?
You have more options. For example, you can rely on your luck and randomly choose one of the algorithms (“Okay, but how should I set its parameters?”) or randomly try several of them (“Which ones? And with what parameters?”). But if you do some research, you’ll come across something called Automated eXplainable AI (AutoXAI) – a way to automatically find a configuration of an explainability algorithm that provides good explanations for a particular task. This is exactly what you were looking for and you can even define what a “good explanation” means for your task.
For more information about AutoXAI, please refer to our previous article.

Thanks to AutoXAI and optimization done in an extensive space of different explainable AI algorithms, you get two that should provide the best explanations based on proxy metrics (this is, in fact, a functionality-grounded evaluation).
Iteration 3: A/B testing with human-centered evaluation
Before you make the explanations available to all administrators, you will test how efficiently they will help them in their work. At the same time, you want to make sure that the explanations that have been identified as the best (measured by the proxy metrics you defined) will be the most useful to people.
So you do an A/B test. One group of administrators will have access to the explanations from the algorithm that emerged from AutoXAI as the best. The next group will get explanations from another, slightly less successful algorithm. The third group of administrators won’t have access to any explanations. You will then let the administrators do their work and objectively measure how much time they need to review the same 200 posts (you can also measure their error rate, for example).

The hypothesis is that administrators who have the seemingly best explanations available should perform the task most effectively. In this case, it should take them the least amount of time. On the opposite side should be the administrators who have received no explanations.
Why do we need to confront human-centered and functionality-grounded evaluation?
In the third iteration, we effectively confronted what the proxy metrics of functionality-grounded evaluation tell us with how different explanations actually helped the person in their work (human-centered evaluation).
There are several very good reasons to do this:
- Proxy metrics may be incomplete or simply ill-defined. For example, it could be that the proxy metrics favored fidelity over understandability and the resulting explanations were too complex, which could do more harm than good (refer to our previous article for more information).
- The set of explainable AI algorithms from which we chose did not contain a single algorithm suitable for our task, so even the explanations provided by the best performing algorithm could have little or no added value for users.
Conclusion
In this part of the series on explainable artificial intelligence, we extended the idea of automated explainable artificial intelligence. We have shown that human-centered and functionality-grounded evaluations of explanations are not mutually exclusive. If we combine them appropriately, we can more reliably verify whether the explanations not only meet some predetermined criteria, but also whether they measurably help those to whom they are intended – the humans.
The PricewaterhouseCoopers Endowment Fund at the Pontis Foundation supported this project.
References
[1] ZHOU, Jianlong, et al. Evaluating the quality of machine learning explanations: A survey on methods and metrics. Electronics, 2021, 10.5: 593.






