What's

Feb 27. 2025
Aiming to Catch’Em All: Our Research on Data for Network Intrusion Detection
We live in a world where Internet connectivity is essential for most people’s daily lives. The Internet plays a crucial role in business operations, online communication, education, or leisure activities. In 2024, 5.5 billion people were estimated to use the Internet (68% of the global population) (Petrosyan, 2024). However, have you ever wondered what would happen if the connectivity, even for a few hours, was unavailable? Such a situation could have various consequences, ranging from mild irritation to revenue losses of billions and even threatening people’s lives. For this reason, cybersecurity must be considered in modern computing systems.
Cybersecurity is generally divided into three main categories: prevention, detection, and reaction. Prevention involves techniques to reduce the attack surface and make the potential cyberattack much harder or even infeasible to perform. Examples include installing software updates, improving systems’ configuration, or employing specialized security mechanisms such as firewalls. However, due to numerous factors (e.g., systems complexity and human error), perfect prevention is unattainable (Apruzzese et al., 2023). For this reason, a significant focus must also be put on cyber attack detection and reaction measures.
Attack detection can be performed at two levels: end-host systems and computer networks. At KInIT, we focus on both areas. Host systems are covered by Martin Mocko, focusing on malware clustering, whereas Patrik Goldschmidt works on a data-centric view of network intrusion detection. This blog post briefly introduces the domain of network intrusion detection (NID) and presents the findings of our recent paper on NID datasets.
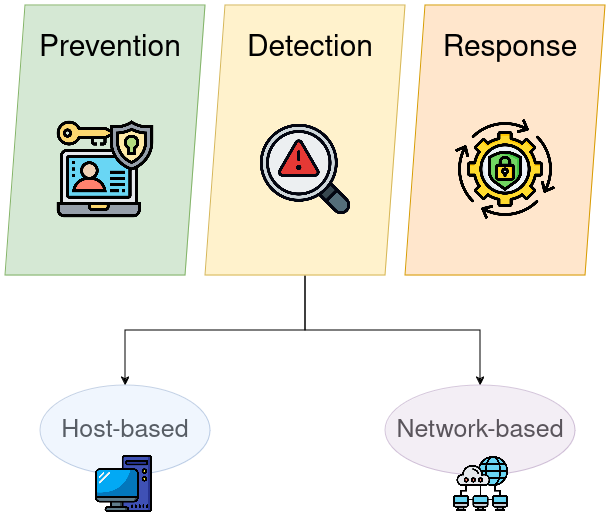
Figure 1: Depiction of three cybersecurity areas: Prevention, Detection, and Response. Research at KInIT primarily focuses on cyber threat detection, which can be further divided into host-based (malware) and network-based detection, detecting malicious activity on a computer network via analysis of its traffic.
Network-Based Intrusion Detection
As mentioned, attack detection can be performed on hosts and networks. Detection on computer networks is performed by Network Intrusion Detection Systems (NIDSs), which are hardware devices or software agents designed to monitor the computer network and identify its potential unauthorised use, misuse, or abuse. Depending on how the attack is detected, we distinguish between signature-based (react on known attack patterns) and anomaly-based (react on unknown deviation from the norm) systems. Although many different approaches can be used for these purposes, machine learning and artificial intelligence methods have proved efficient in many aspects and have become prominent in modern NIDS research.
Regardless of the algorithm or detection method, detection systems aim to maximise the attack detection rate (ideally detect 100% of attacks) while minimising the false alarm rate, i.e., legitimate communication flagged as malicious (ideally 0%). For this purpose, the researchers need various benchmark datasets to evaluate their proposed methods to gauge their potential usefulness in real-world scenarios. However, this aspect is highly problematic due to multiple problems with NID datasets stemming from the characteristics of the NIDS domain.
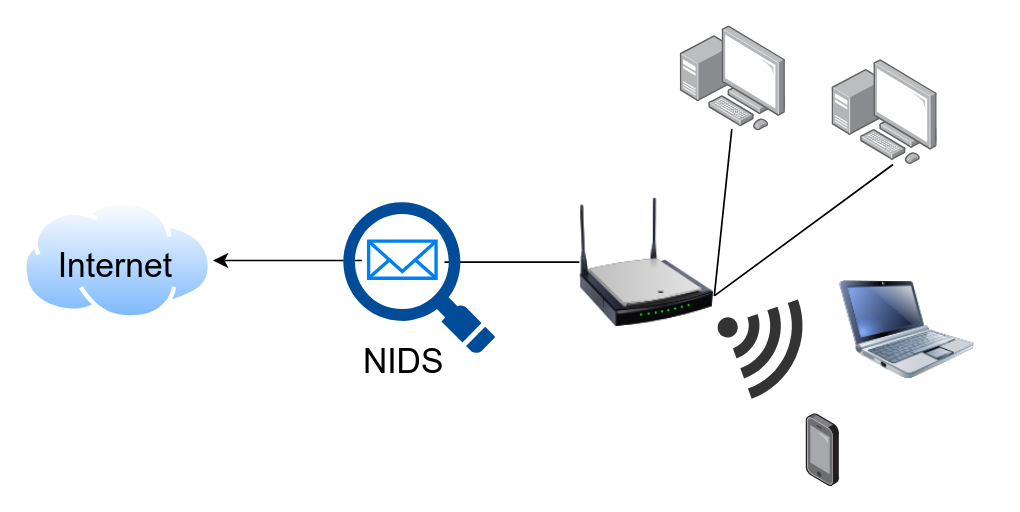
Figure 2: Placement of a network intrusion detection system (NIDS) within a computer network. As depicted, NIDSs are typically placed directly before the Internet gateway, which might also include a firewall. NIDS monitors the activity of a network by inspecting its traffic and raises alerts (or blocks communication directly) if suspicious activity is detected.
Domain-Specific Properties and Their Impact on Data
Unlike typical machine learning (ML) application domains like image or speech processing, network intrusion detection inherits domain-specific properties that significantly constrain the application of data-driven methods like ML. One of such significant properties is variability. In computer networking, each network is unique. Therefore, traffic patterns among networks largely differ. As a result, a detection model trained on one network would likely underperform on the other. In addition, the described inter-network variability is not all. Variability also applies to intra-network traffic, as traffic patterns produced by the same network can drastically change over time. This change, known as concept/model drift, causes performance degradation if a trained model is not periodically updated.
Since NIDSs focus on detecting malicious behavior, attackers naturally try to bypass it. This property of an adversarial environment further degrades the model’s detection performance as attackers explicitly attempt to bypass the method. Other unpleasant domain properties include issues with real-world traffic, as capturing it might compromise users’ privacy, and labeling real-world data cannot be made with absolute certainty. As a result, NID data are often simulated, leading to various issues with realism, as simulated data might not represent real-world data properly.
The above-mentioned domain properties significantly impact the collected data and its quality. As a result, existing datasets contain various limitations that hamper their usage and the reliability of methods using them as a benchmark. As a part of our research, we have identified nine common dataset limitations and divided them into human-caused, domain-caused, and a mix of the two. While human-caused limitations can be entirely addressed by proper data handling, domain-caused limitations are caused by inherent properties of the domain and are thus challenging to address. These limitations are summarised in Figure 3.
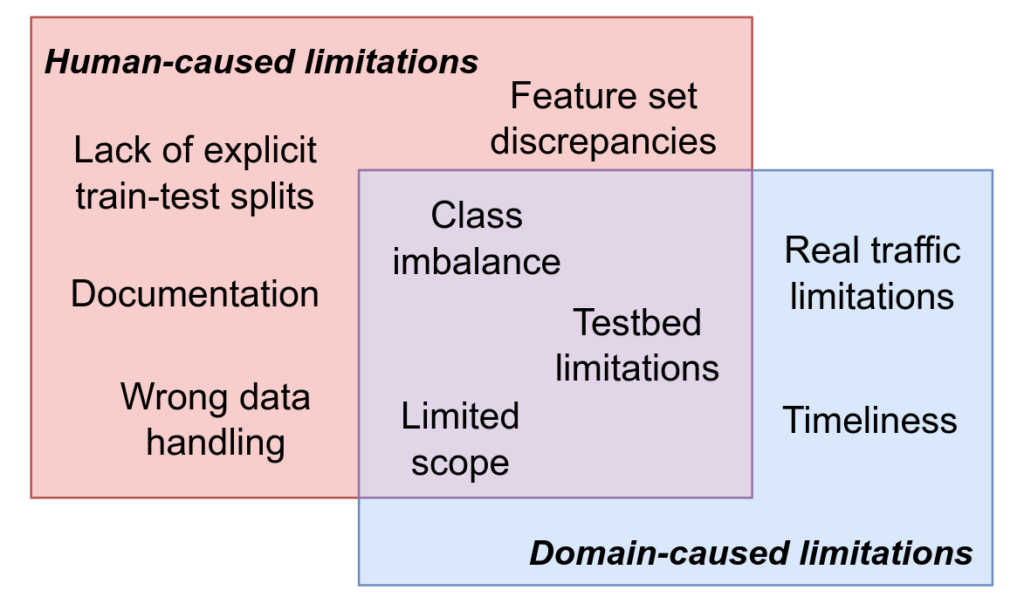
Figure 3: Common limitations of datasets for network intrusion detection. As illustrated, some are a direct consequence of domain-specific properties and are challenging to address (e.g., timeliness), some are primarily caused by a human factor and can be mitigated completely (e.g., documentation), and those that lay in an intersection of both can be addressed only partially (e.g., class imbalance – NID traffic is naturally imbalanced, but data authors might attempt to reduce it)
Arguably, the most pressing issue is data timelines, which stems from heavy concept drift within the domain. When the data is collected, its traffic patterns tend to get outdated rather quickly, thus diminishing the value of the data. As mentioned, real-world traffic brings additional issues, such as labeling uncertainty and privacy concerns, causing many dataset authors to simulate the data via testbeds and synthetic traffic, reducing the data realism. As a result, the lack of realism in benchmark data is considered one of the major obstacles in deploying anomaly-based NIDSs in real-world production environments (Sommer & Paxson, 2010).
Our Research on Network Intrusion Data
Although various NID datasets have been released recently, researchers are often unaware of their suitability for their use cases due to remaining largely unexplored. This fact was a driving factor for our recent paper (Goldschmidt & Chudá, 2025), currently under review in the prestigious scientific journal Computers & Security. In this paper, we synthesise findings on existing data limitations, draw a connection between them and the outlined domain-specific properties, and provide an overview of existing public benchmark datasets suitable for network intrusion detection purposes. In addition, we provided recommendations for correct data selection, usage, and creation for anyone wishing to work with the NID data.
Our paper surveys 89 popular NID datasets across 13 properties by manually downloading and analysing them using exploratory data analysis (EDA) techniques. The paper extracts properties like the dataset volume, duration, types of performed attacks, type of environment, or the network size used to capture the data. For these purposes, we also introduce a new cyber attack taxonomy, and a taxonomy of NID datasets. With all this information, we hope to facilitate future research and development in the NID domain to achieve better replicability, realism, and robustness of the proposed NIDS methods.
In the paper, we present a few interesting findings by analysing the trends of the surveyed datasets. Firstly, we noticed that the traditional KDD ’99 and NSL-KDD that plagued the domain for the past 25 years are no longer the most popular benchmark datasets in novel research. This trend shows that the community has realised how inappropriate these datasets were and has moved to other, more recent datasets, such as CIC-IDS2017. Further analysis of the trends shows the recent boom in dataset publications, as 51 out of 89 surveyed datasets were collected since 2020, as shown in Figure 4. In addition, over three-quarters of these datasets were special-purpose – thus explicitly focused on a particular intrusion type or an environment for their simulation.
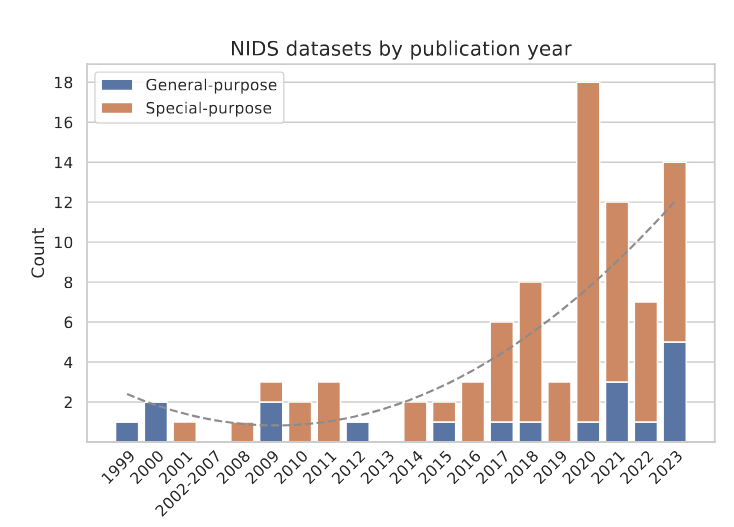
Figure 4: The number of NID datasets by the year of publication. As depicted, the number of released datasets has grown polynomially in the past years.
Analysis of the normal (benign) network traffic has shown that four major approaches are typically used for its generation. These include emulation via usage profiles, emulation via traffic generators, incorporating human actors, and excluding normal traffic entirely. Nevertheless, achieving the realism of normal traffic patterns remains a challenging research topic. On the other hand, generating malicious traffic is more straightforward, as authors can utilise the same tools as real-world attackers for attack emulation. Although synthetic traffic generation is not typical for NID data, it has a huge potential to solve several data-related issues in the future.
What’s Next for Network Intrusion Detection Data Research?
Throughout our survey, we have identified several promising future research and development directions within the NID Data domain. In broad terms, the future research will be centered around one central research question: “How to facilitate access to correct, relevant, and realistic data reflecting the current threat landscape and computer network characteristics of interest?”. Based on this, we split the future research into four main branches – 1) data generation, focused on how to obtain timely and realistic data; 2) data processing, aimed at determining which feature types are the most efficient to detect various attacks; 3) data validation, formalising metrics and methodologies to verify data quality; and finally 4) data publishing, exploring how to get the data to the users faster and with the higher-quality documentation.
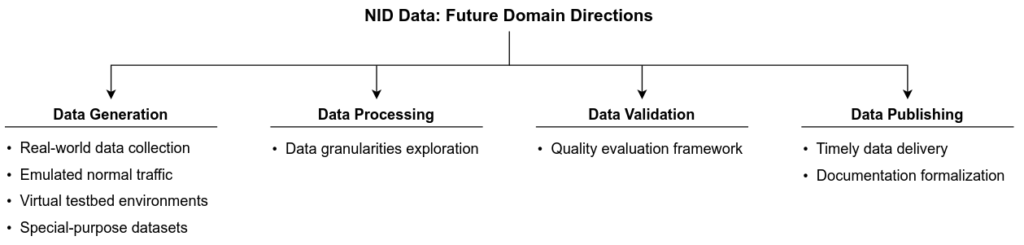
Figure 5: Future NID data research and development directions. We divide them into areas focused on generating, processing, validating, and publishing the data.
One of the most important future directions is to tackle data timeliness and deliver realistic data to end-users faster. In our paper, we proposed adopting the principle of continual dataset capture from a real-world environment and its subsequent automatic labeling and publishing. Similar projects, such as MAWILab or Kyoto 2006+, were available in the past, but we are not aware of any similar projects nowadays. Therefore, such a project is highly desired to allow researchers and practitioners to access the newest traffic patterns and benchmark their proposed systems with them. However, continual data capture requires advancements in other aspects, such as accurate real-world data labeling, which is essential for the final data quality.
In summary, network intrusion detection is an example of a classic cybersecurity cat-and-mouse game, where good actors are constantly pursuing the bad ones, always being able to come up with more sophisticated and stealthy attacks. Nevertheless, through continual research on the topic, we believe NIDSs and other cybersecurity mechanisms will provide sufficient security for most Internet users.
Conclusions
Data is at the heart of any machine learning system. As most NIDS research relies on machine learning nowadays, ensuring the highest data quality is essential in order to move the research in the domain forward. As discussed throughout our research paper, several limitations of the data are hampering the advancements of NIDS research and are limiting the soundness of achieved results. In our article, we have outlined these limitations, proposed future research as their potential remedies, and listed the available benchmark datasets, hoping to guide future NIDS research toward better robustness and reliability. If you wish to learn more, read the paper’s preprint at arXiv.org (Goldschmidt & Chudá, 2025).
References
Apruzzese, G., Laskov, P., & Johannes. (2023, 06 31). SoK: Pragmatic Assessment of Machine Learning for Network Intrusion Detection. 2023 IEEE 8th European Symposium on Security and Privacy (EuroS&P), 592-614. 10.1109/EuroSP57164.2023.00042
Goldschmidt, P., & Chudá, D. (2025, 02). Network Intrusion Datasets: A Survey, Limitations, and Recommendations. ArXiv. 10.48550/arXiv.2502.06688
Petrosyan, A. (2024, December 12). Number of internet users worldwide 2024. Statista. Retrieved 2025-02-04. www.statista.com/statistics/273018/number-of-internet-users-worldwide/
Sommer, R., & Paxson, V. (2010). Outside the Closed World: On Using Machine Learning for Network Intrusion Detection. In 2010 IEEE Symposium on Security and Privacy (pp. 305-316). IEEE. 10.1109/SP.2010.25
These activities were supported by the Pontis Foundation, PwC Slovakia Endowment Fund at the Nadácia Pontis/Pontis Foundation and IFT INFORM TECHNOLOGIES, a. s.