


Pojmy ako predsudok či skreslenie môžeme chápať mnohými spôsobmi, či už v pozitívnom alebo negatívnom význame. Poznáme mnoho typov predsudkov, akými sú napríklad spoločenské a historické predsudky či predsudky v reprezentácii. Spoločenské predsudky môžeme vnímať aj ako isté stereotypy, ktoré sú založené na demografických faktoroch či fyzických charakteristikách, napríklad s ohľadom na rasu, etnický pôvod, pohlavie, sexuálnu orientáciu, socioekonomický status alebo vzdelanie.
Tieto stereotypy vnímame v prevažnej miere ako nespravodlivé. A zdá sa, že ani systémy umelej inteligencie nedokážu byť úplne spravodlivé. Platí to najmä pre tie algoritmy, ktoré sa učia z dát, keďže tie už určité skreslenia môžu v sebe obsahovať.
To však neznamená, že by sme mali s takouto situáciou zmieriť. Pretože ak má byť naším cieľom minimalizovať potenciálne riziká umelej inteligencie skôr, než spôsobia ľuďom neželanú ujmu, potom je nevyhnutné, aby sme lepšie porozumeli aj mechanizmom, ktoré stoja za jej predsudkami.
Umelá inteligencia nepreberá od nás iba užitočné znalosti. Niekedy si osvojí aj naše predsudky a stereotypy. Žiaľ, o predsudkoch modelov umelej inteligencie pracujúcich so slovenčinou nevieme takmer nič. To sa však chystáme zmeniť.
Online workshop: Rodové predsudky v umelej inteligencii
Spolupráca ľudí z rôznych oblastí vedy a výskumu je často vzájomne obohacujúca a potrebná, zvlášť, ak sa týka skúmania a riešenia problémov, ktorých povaha je komplexnejšia. Tak je tomu aj v prípade výskumu na poli predsudkov v umelej inteligencii. Ich porozumenie a riešenie si vyžaduje spojenie síl viacerých vedných disciplín, výskumných prístupov a pohľadov, ktoré ponúka napríklad informatika (zvlášť odbor umelej inteligencie), etika, či dokonca rodové štúdiá skúmajúce význam rodu v kultúre, spoločnosti a vede.
V snahe o interdisciplinárny prístup sa v priebehu marca uskutočnil online workshop s názvom Rodové predsudky v umelej inteligencii, ktorého sa zúčastnili okrem výskumníkov a výskumníčok KInITu aj rodové expertky. Hlavným cieľom stretnutia bolo získať poučenie i usmernenie, týkajúce sa odbornejšieho zohľadnenia témy rodu v projekte Spoločenské predsudky v slovenskej AI. Tiež sme chceli zistiť, či existuje na Slovensku reprezentatívny zoznam rodových stereotypov, resp. korpus jazykových výrazov obsahujúcich rodové predsudky, s ktorým by bolo možné ďalej experimentálne pracovať. Získané poznatky a poskytnuté informačné zdroje by mali prispieť k výstupom projektu, ktoré povedú k lepšiemu porozumeniu problematiky predsudkov v umelej inteligencii na Slovensku.
Obsahom workshopu bolo predstavenie projektu, súvisiacich výskumných činností vrátane plánovaných experimentov a predstavenie problematiky jazykových modelov založených na umelej inteligencii. Následná diskusia o metodologických aspektoch daného výskumu a o povahe rodových predsudkov priniesla možnosť porovnať a obohatiť pohľady výskumníkov a výskumníčok.
Výsledkom diskusie bolo napríklad zistenie, že síce reprezentatívny korpus jazykových výrazov obsahujúcich rodové predsudky v slovenskom jazyku nemáme, no pomocou rôznych zdrojov (napr. EIGE reportu – A study of collected narratives on gender perceptions in the 27 EU Member States) je možné zostaviť zoznam rodových stereotypov. Tento zoznam bude slúžiť ako základ pre vytváranie datasetov, obsahujúcich rôzne jazykové výrazy určené k testovaniu jazykových modelov založených na umelej inteligencii. Už počas workshopu sa podarilo zadefinovať základné prvky takéhoto zoznamu. Vytvorila sa tak mapa základných oblastí a tém, v ktorých sa rodové stereotypy a predsudky objavujú, a ktoré by mal akýkoľvek reprezentatívny zoznam stereotypov obsiahnuť (viď. obrázok).
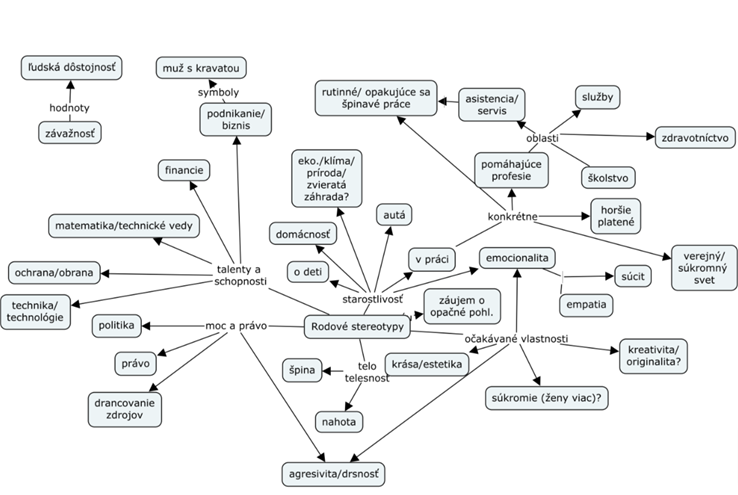
Za účasť na workshope sme vďační rodovým expertkám Adriane Jesenkovej, Mariane Szapuovej, Jane Jablonickej Zezulovej, Jane Valdrovej a Veronike Valkovičovej.
Posúdenie z hľadiska dátovej etiky
V rámci riešenia projektu Spoločenské predsudky v slovenskej AI sa v mesiacoch február-apríl 2023 uskutočnil proces posúdenia z hľadiska dátovej etiky (data-ethics assessment) pod vedením výskumníkov z KInIT tímu Etika a ľudské hodnoty v technológiách. Posúdenie bolo zamerané predovšetkým na prácu s etickými rizikami ohľadom zberu, používania i publikovania dát v kontexte výskumných úloh projektu. Zmysel takéhoto posúdenia spočíva predovšetkým v snahe vyhnúť sa neetickému konaniu v zmysle nedodržiavania určitých etických princípov či porušovania hodnôt pri práci s dátami. Neetické konanie prináša so sebou rôzne negatívne dôsledky a znižuje aj kvalitu vedecko-výskumnej práce. Okrem toho proces etického posúdenia do istej miery aj formuje spôsob etického myslenia výskumníkov a výskumníčok.
Data-ethics assessment prebiehal najmä formou viacerých pracovných workshopov, ktorých sa zúčastňovali výskumníci participujúci na projektových úlohách – najmä tí, ktorých sa práca s dátami priamo týkala. Proces posúdenia pozostával z viacerých fáz. Medzi kľúčové patrili predovšetkým identifikácia zainteresovaných strán (stakeholderov), identifikácia etických problémov a manažment rizík, ktorého súčasťou bola identifikácia rizík, meranie pravdepodobnosti ich výskytu, závažnosti ich dopadov a navrhovanie vhodných protiopatrení, pomocou ktorých by bolo možným rizikám predchádzať, prípadne ich negatívny dopad na stakeholderov aspoň minimalizovať.
Dôležitou súčasťou etických posúdení bolo aj vyjasnenie si motívov, cieľov a benefitov výskumu. Jedným z podstatných impulzov etického posúdenia bola aj výzva k zapojeniu ľudí s rodovou expertízou ako významného stakeholdera. Zapojili sme ich do samotného procesu posúdenia a podieľali sa aj na plnení niektorých cieľov projektu. Táto výzva sa premietla napríklad do realizácie expertného workshopu, o ktorom sa dočítate viac vyššie na tejto stránke.
Záverečné podujatie: Spoločenské predsudky v slovenskej AI
Výstupy projektu sme predstavili 18. októbra 2023. Záznam z podujatia si môžete pozrieť tu:
Výsledky
- Správa o súčasnom stave spoločenských predsudkov v slovenskej umelej inteligencii – správa dokumentuje našu prácu a poskytuje informácie o hlavných zisteniach (report je v anglickom jazyku). Cieľom tejto správy je poskytnúť informácie pre širokú verejnosť aj odborníkov v oblasti umelej inteligencie. Jedným z hlavných cieľov je zvýšiť povedomie o tejto problematike. Okrem toho správa poskytuje aj všeobecný prehľad o našom projekte a môže slúžiť výskumníkom na analýzu našej práce a výsledkov.
- Dáta a technické informácie – údaje, ktoré sme zhromaždili pre rôzne typy systémov umelej inteligencie, môžu použiť vývojári a výskumníci umelej inteligencie na meranie a riešenie predsudkov vo svojich systémoch umelej inteligencie. Všetky dáta sme zverejnili a sú voľne dostupné. Hoci sa zameriavame na slovenčinu, údaje sa dajú opätovne použiť na štúdium tejto problematiky aj v iných jazykoch.
