


Čo je


okt 19. 2023
Modern Unsupervised Learning – Can We Bootstrap Our Own Latent?
This blog post is a part of the EEML Summer School 2023 series. It’s a series of impressions that we, as doctoral students, got from attending the EEML Summer School 2023 in Košice, Slovakia.

AI solutions, mainly deep neural networks nowadays, are often used to create useful representations of the problem we have at hand. These can, for example, be representations of images, videos, sounds, text, user behavior, behavior of programs, and much much more. In the past, supervised solutions achieved much better results in terms of good representations of these modalities.
However, the situation is slowly changing with the advent of new unsupervised learning solutions. In this post, we will introduce one of them – Bootstrap Your Own Latent (BYOL). BYOL is inspired by previously published contrastive learning methods, although it cannot be strictly considered a contrastive learning method. It was introduced to us at the Eastern European Machine Learning Summer School 2023 by one of its authors, Michal Valko.
Contrastive learning
Typical contrastive learning methods work based on a relatively simple concept. They repulse different images (negative pairs) while attracting the same image’s two views (positive pairs) [1]. Negative pairs are primarily used so that the learned solution (data representation) does not degenerate into a collapsed solution – i.e. where the same vector would represent all images.
Typically, one would require a lot of negative samples in each training step. This is because there are, let’s say, much fewer ways of how one can be a dog than the ways that one can not be a dog. There are, for example, other animals, like cats, mice, and birds (which are not dogs), but there are also many different other things that are not dogs – like cars, houses, mountains, lakes, etc. Often, to get a good representation, the method needs to understand these differences. An example of what pairs could be used in 1 round (batch) of training a contrastive learning method is depicted in Figure 2.

Bootstrap Your Own Latent (BYOL)
Bootstrap Your Own Latent (BYOL) is different from typical contrastive learning methods because it does not utilize any negative pairs. This could help researchers working with other data modalities than images because finding the “right” negative examples for speech, sound, text, or other kinds of data could often be challenging. The authors of BYOL worked with images. So to make things easier, when talking about data in this article, we will talk primarily about images.
The main idea of BYOL is to use bootstrapping (in its idiomatic sense) – i.e., to gradually improve upon itself (its representation of images) without some new external guidance – a self-learning, continual self-improving process. The hope is that such a bootstrapping approach will help avoid solution collapse. The term bootstrapping originates from the English idiom “to pull oneself by their own bootstraps” – meaning that a person should be able to improve by themselves without external help. This is also why pulling boots by the bootstraps is the headline image of our blog post (Figure 1).
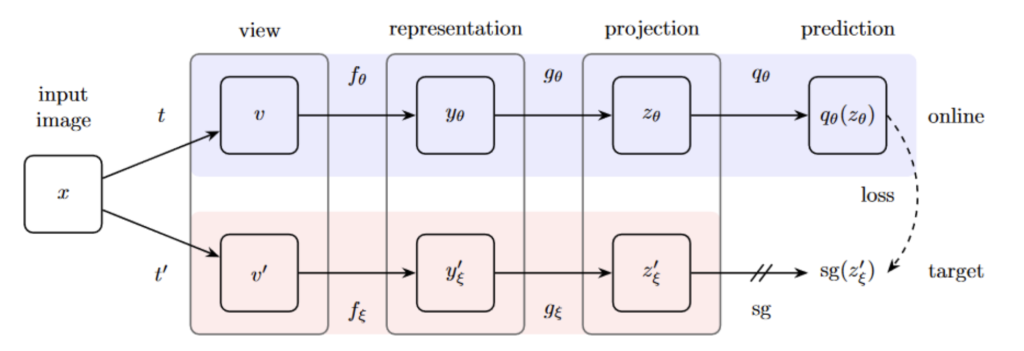
Specifically for BYOL, bootstrapping is done on the projections of image representations. This is achieved by utilizing two neural networks – one online network and one target network. Figure 3 shows the architecture of BYOL. The BYOL process is also explained in the figure description. The bootstrapping works in a way that the online network tries to predict the projection of the target network. Only the online network receives gradient updates. The target network’s weights are set as the exponential moving average of the sequence of weights of the online network.
BYOL’s results
BYOL achieves results that are on par, if not better than, the state-of-the-art (SotA) solutions – like SimCLR (a strong baseline) and MoCo. Both MoCo and SimCLR are unsupervised baselines. On ImageNet with linear evaluation, BYOL achieved the best results out of the evaluated unsupervised methods for various levels of the number of parameters. The evaluation can be found in Figure 4. Its results reach very close to the Supervised solutions, which is a tough baseline to beat since these solutions have the advantage of utilizing image labels in their learning process – a luxury that BYOL does without.

BYOL-Explore: Moving beyond image representations
Enter the world of reinforcement learning (“RL” in short). In such a world, we try to create an autonomous agent that will be able to make decisions on its own based on its environment and the target goal that they have. There are many applications of RL agents in specific environments – such as AlphaZero for playing chess, AlphaGo for playing Go, or even OpenAI Five for playing Dota 2. For BYOL-Explore, we consider RL agents that act in computer games. For an agent to be effective in such a world, it needs to have some model of the world (i.e. the game) – a “world model”. In these complex environments, it is completely infeasible for an agent to explore everything and go to every place. Therefore, the agent needs to learn to intelligently prioritize the areas where it expects to achieve a better reward.
BYOL-Explore is one such instantiation of an RL agent. It instantiates its world model by using BYOL. Afterwards, it improves on the standard BYOL model using curiosity-driven exploration of the game. This can also be considered a form of bootstrapping – the term we used to explain the learning process for the simple BYOL model itself. In this way, BYOL-Explore slowly trains itself to recognize what is interesting and what should be explored – a crucial thing that needs to be done to avoid path explosion (the explosion of the possible combinations of environments and actions) and move towards the goal.
The improvement of the model is done in the following way:
- The agent asks the model “questions” about the world – particularly “what can be found behind these doors”, etc.
- The agent notes where the model makes mistakes.
- The agent is rewarded for fooling the model (or rather finding where it makes mistakes).
By following this training pattern, the agent tries to find places/things in the game that are unexpected for the model and gets rewarded for it. This helps the agent create a better world model. If the model is trained well, achieving the agent’s goal should be much easier – i.e. to pass to another level or perform some tasks that give rewards.
In this video, we can see the BYOL-Explore agent solving a particular in-game task called Throw Across. The model only sees the images (video) that we can see under the “First person” category. The “Following” and “Top down” views serve us to understand better what is going on in the game. All in all, BYOL-Explore solved tasks which were previously not solved without utilizing “human help” – i.e. without path mimicking (human demonstration), which is a very nice accomplishment. It solved 5.5 out of 8 tasks on DeepMind’s set of 8 problem tasks, called DM-Hard-8, which require exploration in partially observable environments to solve them.
Can BYOL be successfully applied in the malware domain?
As a bonus, we also decided to briefly write about whether BYOL can be utilized in our related research as well. One of the PhD theses here at KInIT is in the field of malware, specifically how to create the best clustering models in this domain. The most common tools that are also most frequently used for malware clustering have some limitations. If one wants to create a really powerful clustering model, these common tools are insufficient. Therefore, our mission for the upcoming weeks and months is to improve the state-of-the-art results in malware clustering by utilizing some form of self-supervised learning. More specifically, models like BYOL seem to be ideal candidates, since they allow us to worry less about the negative samples that we would otherwise need to use.
The modern self-supervised learning solutions such as BYOL, however, still require some form of data transformations to be able to work correctly. This is relatively easily done in the domain of image transformations – since one can utilize rotations, crops, image masks, etc. In the malware domain, it is a much more difficult problem to find the right kind of transformations. We hypothesize that, if one were to have a big dataset of samples that is rich enough, it could be possible to train SSL methods just based on the samples that are in the dataset without the utilization of data transformations. Malware is often found in many different, but very similar, variations in the wild. This could serve as natural forms of data transformations that one does not need to create by themselves. Alternatively, there are some kinds of data transformations of executable programs that do not change the executability or the maliciousness of the program that also can be utilized. However, such transformations could by some experts be deemed relatively trivial. It is an open question whether such transformations could help an SSL method learn a better representation.
All in all, we believe that representations, such as those that an Autoencoder model can learn, can be enhanced by training the model to specifically learn to put some samples closer together. As far as we know, models like BYOL have never been tried before in the malware domain for malware clustering. Therefore, this is a fascinating research avenue for us.
Conclusion
We were inspired to write this article to bring the readers’ attention to the relatively recent new developments in the field of deep learning, particularly self-supervised learning. Self-supervised learning is a new way for researchers in academia and in practice to achieve state-of-the-art results based on representations learned in a practically fully unsupervised context.
BYOL is an example of a well-engineered method which can achieve near-supervised learning performance on ImageNet. It does not mean, however, that it cannot reach it and even move beyond the performance of the supervised methods.
The data labels help neural networks achieve a well-trained model in a relatively short time. However, the labels could also sometimes be a limit to the potential of the learned representations – since the labels of the images can inherently include some bias, or due to errors could even be flat-out wrong in some cases.
Michal Valko – a short bio
Michal is an accomplished researcher in the field of AI who currently works at Google DeepMind in Paris. He specializes in learning representations that require little-to-no human supervision. This includes deep reinforcement learning, bandit algorithms, or self-supervised learning. Besides being a successful AI researcher, he is also a Slovak with roots in Košice. We imagine that organizing and participating in EEML 2023 in Slovakia must have been a small dream come true for him.

References:
[1] Chen, X. and He, K., 2021. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 15750-15758).
[2] Grill, J.B., Strub, F., Altché, F., Tallec, C., Richemond, P., Buchatskaya, E., Doersch, C., Avila Pires, B., Guo, Z., Gheshlaghi Azar, M. and Piot, B., 2020. Bootstrap your own latent – a new approach to self-supervised learning. Advances in neural information processing systems, 33, pp.21271-21284.

