

What's

Sep 6. 2021
Cross-Lingual Learning bridges inequalities among languages
Matúš Pikuliak is our new successfully graduated PhD in KinIT. In his research, he focused on methods that should bridge inequalities among languages and offer useful applications to people and communities that have not yet been able to take full advantage of the progress based on deep learning in their mother tongue.
In recent years, deep learning has brought significant advances in natural language processing. Machine translation, information retrieval, speech transcription and other applications that we commonly use today, have achieved significant improvements thanks to deep learning. Similar to other domains, this progress is dependent on the collection of datasets which enable machine learning models to learn to perform a given task. For various historical, sociological, technological and other reasons, some languages (e.g. English, Mandarin Chinese) are very popular today, are spoken by billions of people and abundant artificial intelligence research is carried out with them. On the other hand, there are thousands of marginal languages, they are spoken by a much lower number of people and the new texts are generated in much lower volume in comparison with other languages. The use of artificial intelligence approaches is often much more complicated and sometimes impossible, especially because there are no large enough datasets for these languages.
Matúš is our last doctoral student recruited, who has recently defended his PhD degree. In his research, he focused on methods that should bridge inequalities among languages and offer useful applications to people and communities that have not yet been able to take full advantage of the progress based on deep learning in their mother tongue. He explored the possibilities of the so-called cross-lingual learning. It is a machine learning paradigm where knowledge and data created in one language are transferred to other languages, using various techniques. For example, if artificial intelligence learns to solve the problem of information retrieval in English, the aim of these techniques is to transfer this knowledge to other languages so that we can also search for information in them.
One of the very first literature reviews in this area was part of Matúš’s work and it was published in the journal Expert Systems With Application (in Google Scholar it is a journal from the Artificial Intelligence section with the highest h-index). The basis of this review was mapping of the approaches in cross-lingual learning used so far and more than 170 existing works were analyzed. A thorough analysis of the languages, datasets, tasks and approaches used, provided an insight into the state of the area, which we had lacked by then. Cross-lingual learning has proven to be a very versatile technology, applicable to any natural language processing task. Also, the dominance of major European languages in experimental work has been proven. Despite the fact that one of the main reasons for cross-lingual learning is to help languages with a lack of data, experimental verification is often carried out in languages that may not even need such help. Matúš also contributed to the theoretical understanding of such learning by formally defining it and proposing a division of existing approaches according to the type of knowledge used to communicate between different languages. In this way, sample annotations, sample features, parameter rates, and internal model representations can spread between languages.
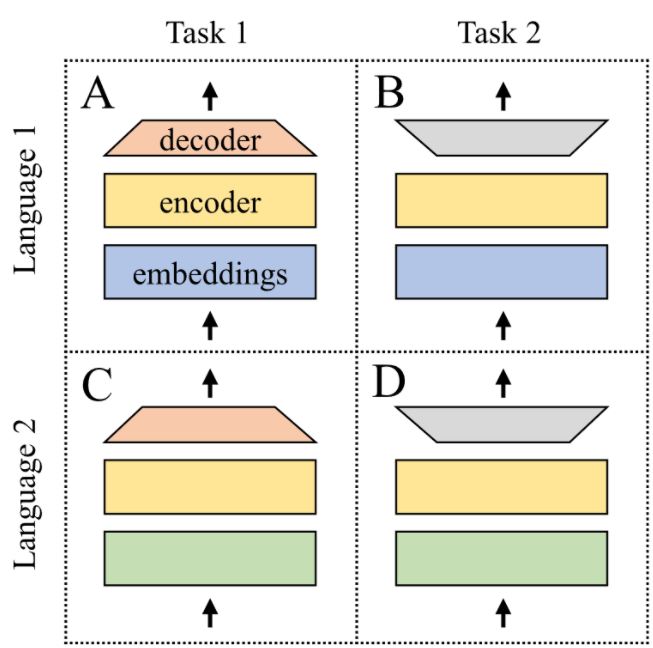
Based on this analysis of the state of the area, Matúš then focused on the combination of multilingual and multitask learning. It was common to study these two approaches separately. Here, Matúš decided to combine them and explore the possibilities and limitations of such a connection. The experiments were carried out with the so-called grid of models. Each model had a specific task defined in a specific language and together they covered all possible combinations of the selected 4 tasks and 4 languages. Models in such a grid have learnt to solve a problem based on their data. At the same time, they also learned from each other through a mechanism called parameter sharing. The results of the experiments were discoveries in how to combine data from different languages properly, in order to maximize the performance of models in less studied languages.
The research has the potential to be applied in practice in the development of methods and models in “poor” languages. Slovak language can also be included in these “poor” languages in some cases. By transferring knowledge from rich languages using the proposed methods, we can improve the results for these languages. These technologies are already helping people today, public machine translators (e. g. Google Translate) already use such techniques and translations into and from less common languages are becoming better thanks to the transfer of knowledge. This is another step in the ongoing democratization of artificial intelligence and information technology in general. In addition, working with multiple languages is proving to be an interesting challenge for other KInIT activities, where we can use similar techniques in our existing projects focused on e. g. combating misinformation or in various research projects of our partners.
Selection from Matúš’s publications:
1. Pikuliak, M., Šimko, M., & Bielikova, M. (2021). Cross-lingual learning for text processing: A survey. Expert Systems with Applications, 165, 113765.
2. Pikuliak, M., Simko, M., & Bielikova, M. (2019, January). Towards combining multitask and multilingual learning. In International Conference on Current Trends in Theory and Practice of Informatics (pp. 435-446). Springer, Cham.

